密码学基础之线性代数Ⅱ
后半部分的视频建议反复观看。
[TOC]
07 点积与对偶性

引入点积的标准方法只需要向量的基础认识即可,但想要理解点积所发挥的作用,只能从线性变换的角度才能完成。(这是为什么把点积的内容放在如此后面的原因)
首先我们知道的是,两个向量的点积就是将对应项相乘再求和

点积的几何解释相信大家在高中也是有学习过
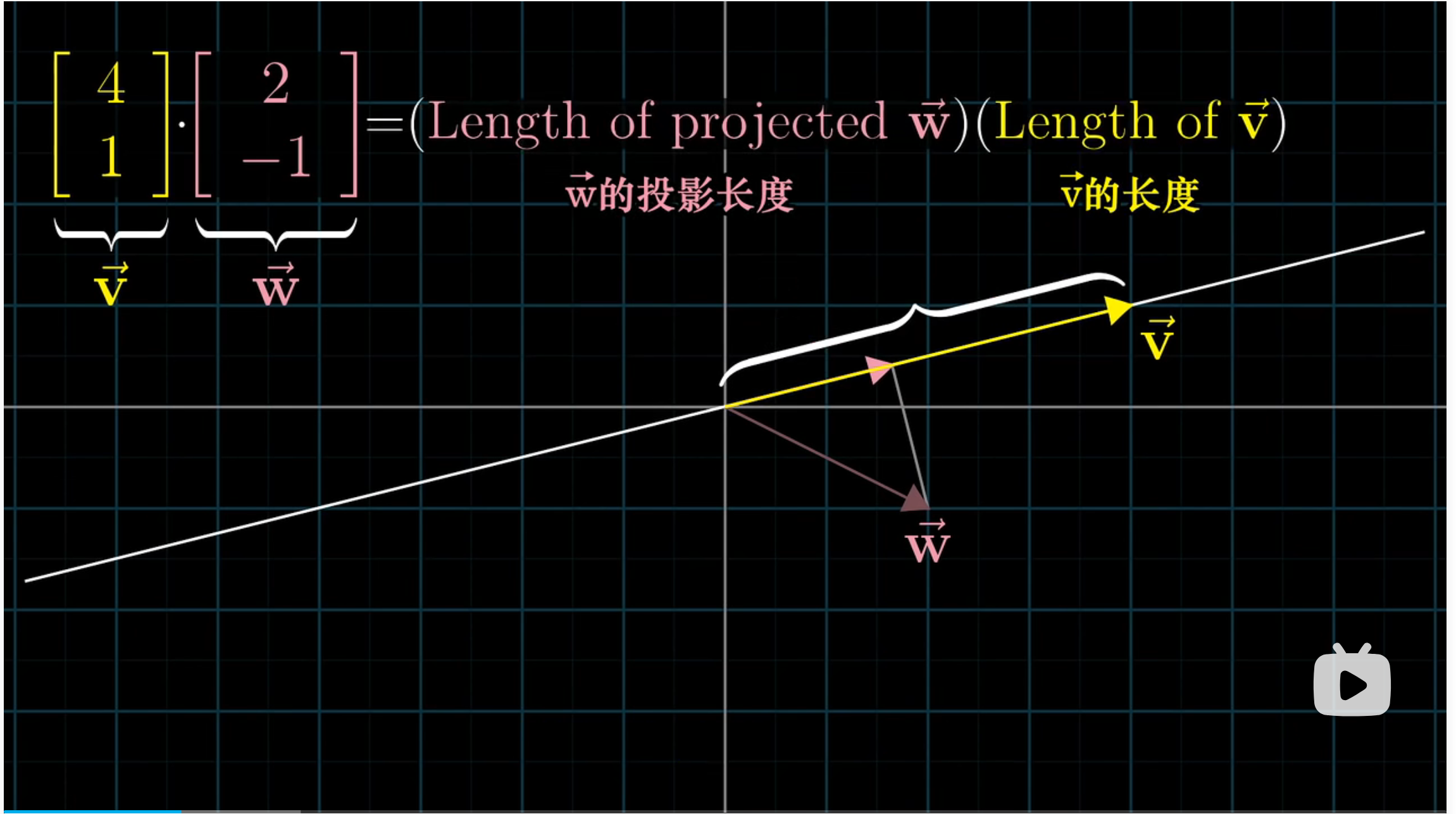
如果向量 $w$ 在 $v$ 方向上投影与 $v$ 的方向相反,则结果取负值。
如果向量 $w$ 和 $v$ 相互垂直,则点积为零。
但如果以投影的方式去理解,为什么点积的运算会与顺序无关呢?$w$ 的投影长度 乘以 $v$ 的长度 和 $v$ 的投影长度 乘以 $w$ 的长度 结果为什么会一样呢?
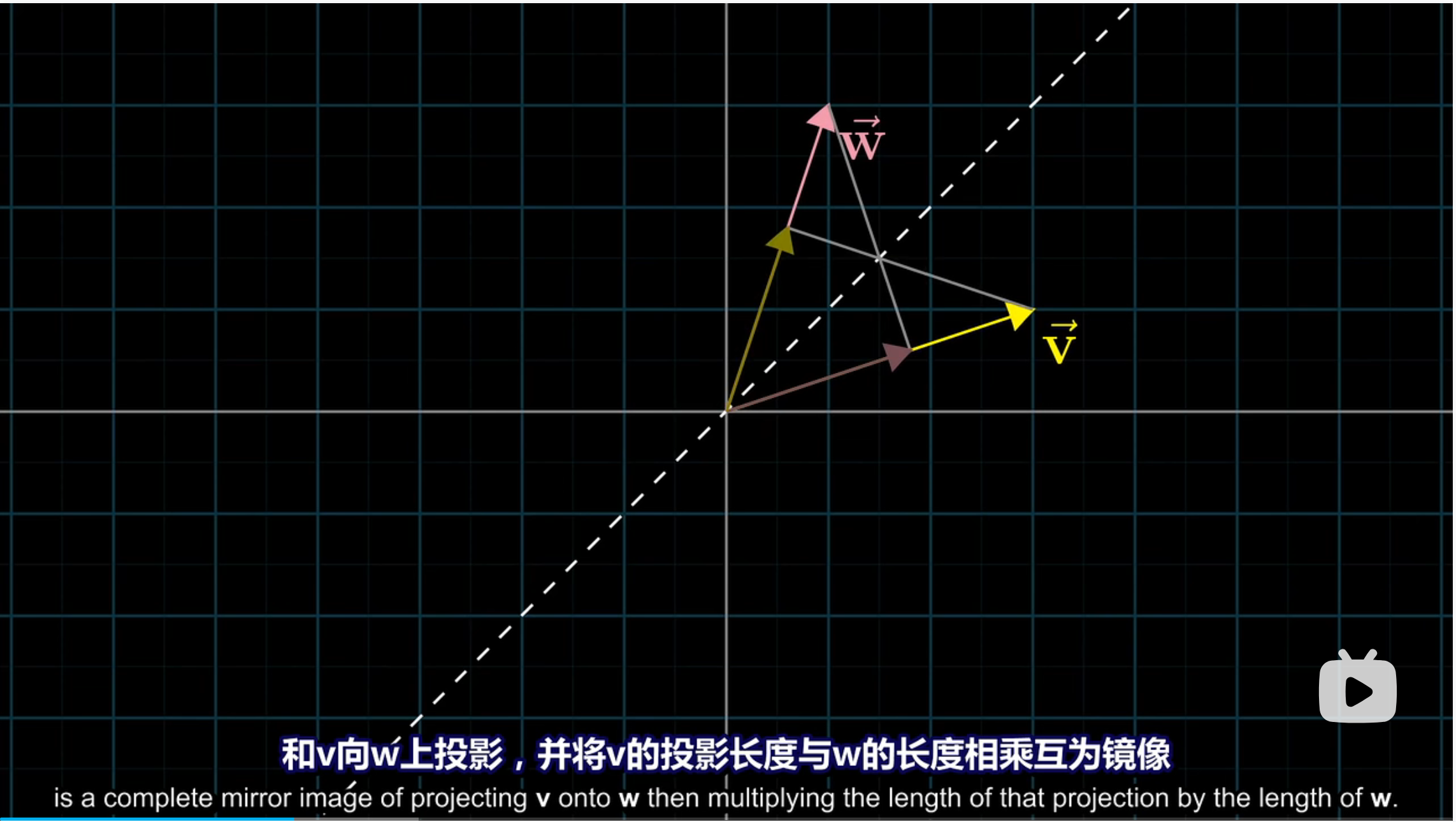
思考一下,如果 $w,v$ 是两个长度相同,方向不同的向量,我们可以在他们中间做一条对称轴。这样它们彼此的投影就互为镜像,那么很自然的向量相乘的结果就是一样的。
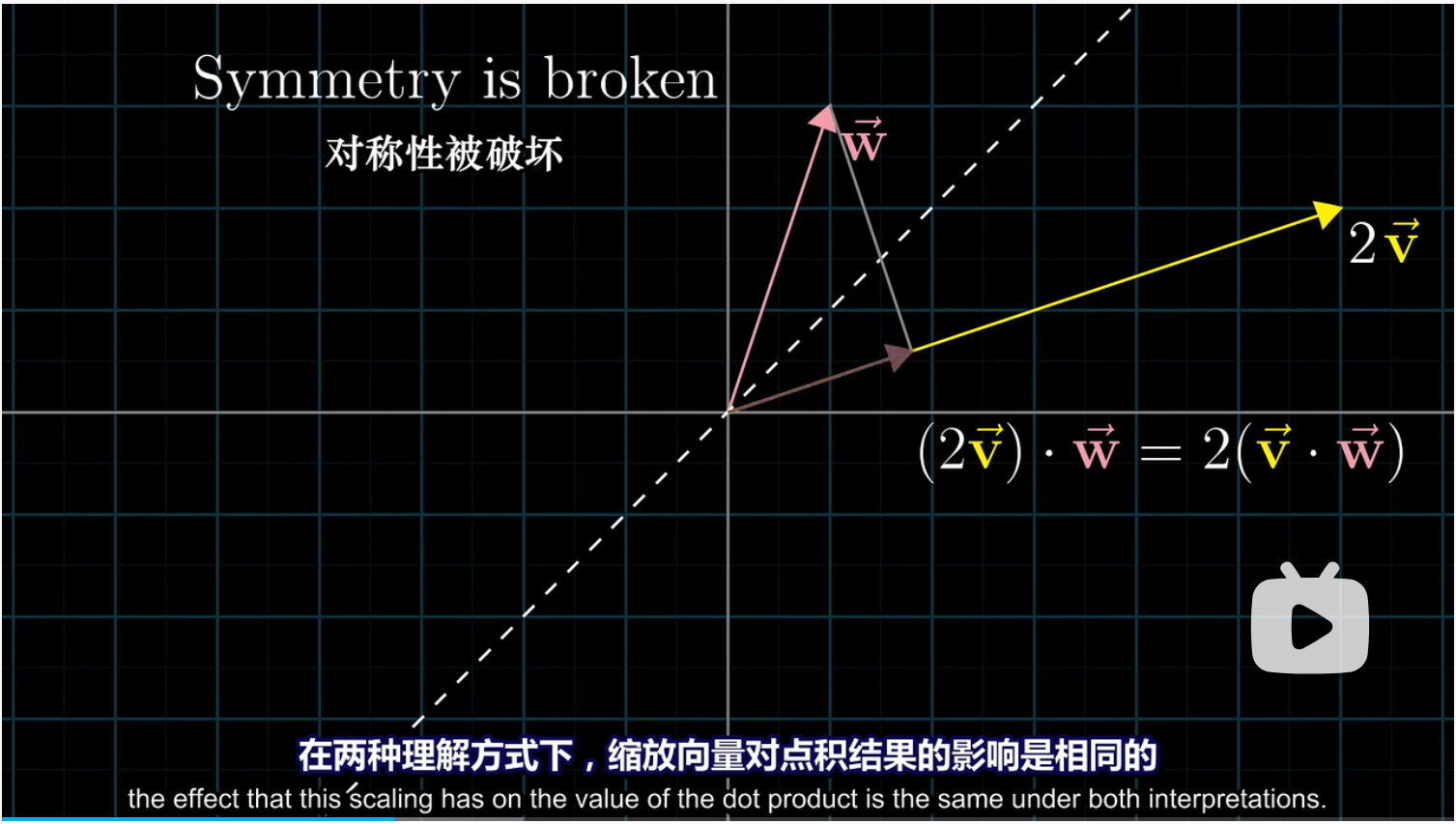
现在我们破坏它们的对称性,将向量 $v$ 拉长为原来的两倍;此时 $w$ 在 $2v$ 上的投影不变,因此 $2v$ 点乘 $w$ 就应该恰好是 $v$ 点乘 $w$ 的两倍,即 $(2v)\cdot w = 2(v\cdot w)$。
但我们反过来将 $v$ 投影在 $w$ 上,显然 $v$ 的长度变为原来两倍的话,投影的长度肯定也会变为原来两倍,而 $w$ 的长度不变,因此总体效果仍然是点积变为两倍。
因此,对称性被破坏后,两种投影方式下,缩放向量对点积结果的影响都是相同的。

那么,为什么向量对应坐标相乘然后求和,和投影有所联系呢?这就引出了 ”对偶性“ 概念。
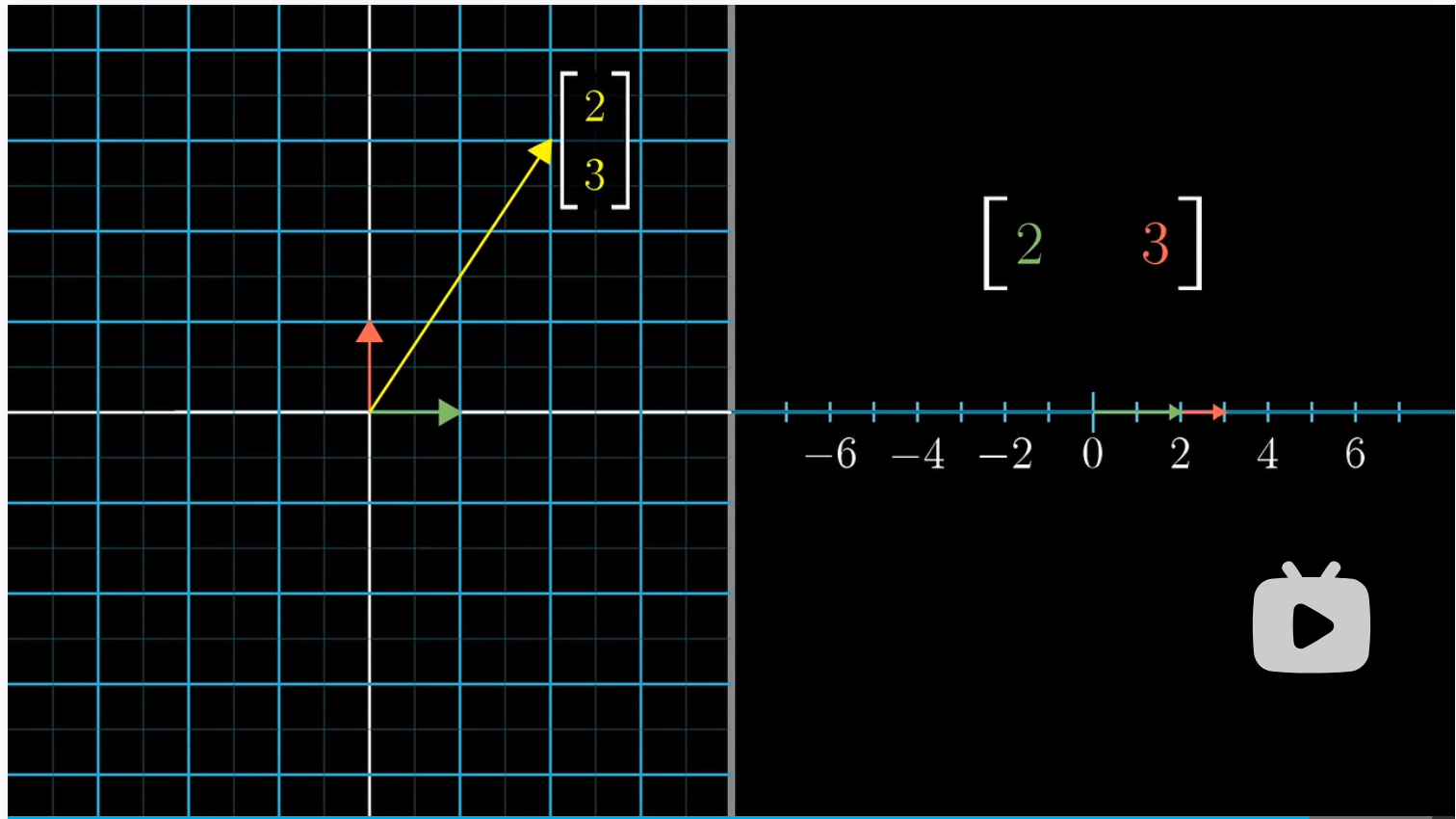
举例我们有一个非方阵 $[a \ b]$ ,很显然它所代表的线性变换会将一个二维空间都压缩到一条直线上,因此对于一个向量 $\left[ \begin{array}{l} x \ y \end{array} \right]$,对其应用线性变换后的坐标为 $[a \ b]\left[ \begin{array}{l} x \ y \end{array} \right] =ax + by$ 。 这是矩阵向量乘积。
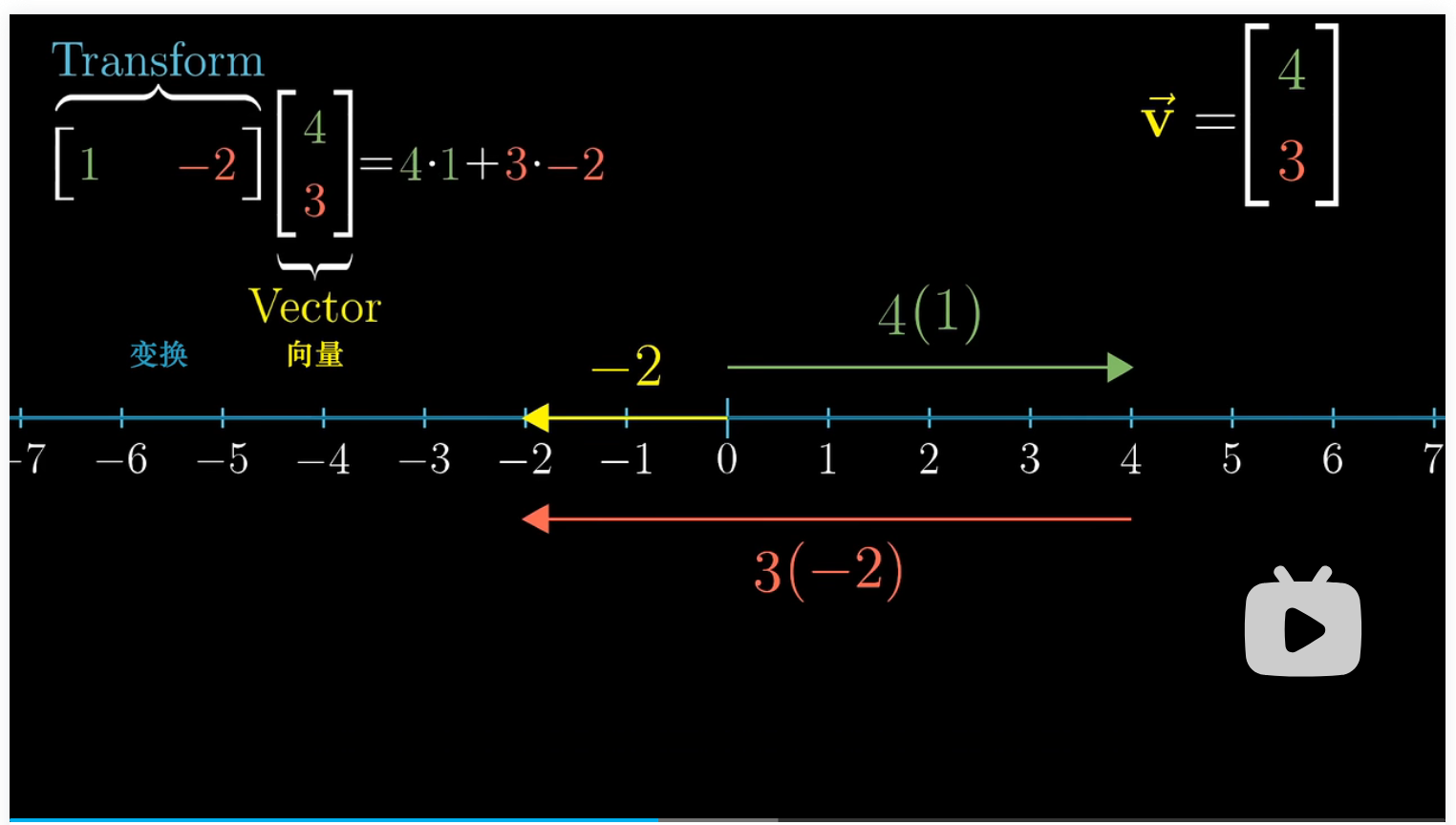
现在我们考虑两个向量相乘,我们将一个数轴斜向放置在二维平面中,并记二维平面中有一个单位向量 $\hat u$
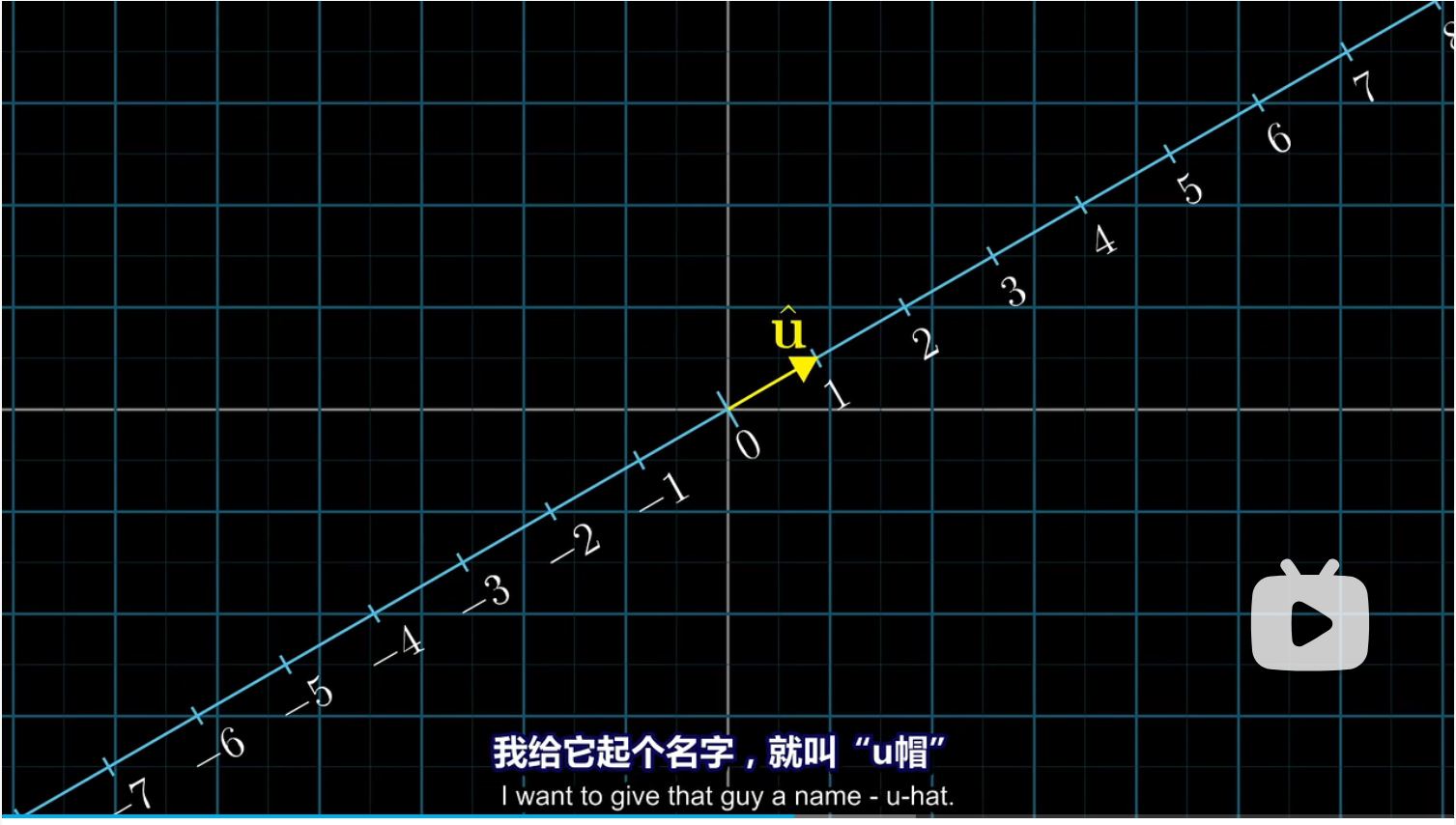
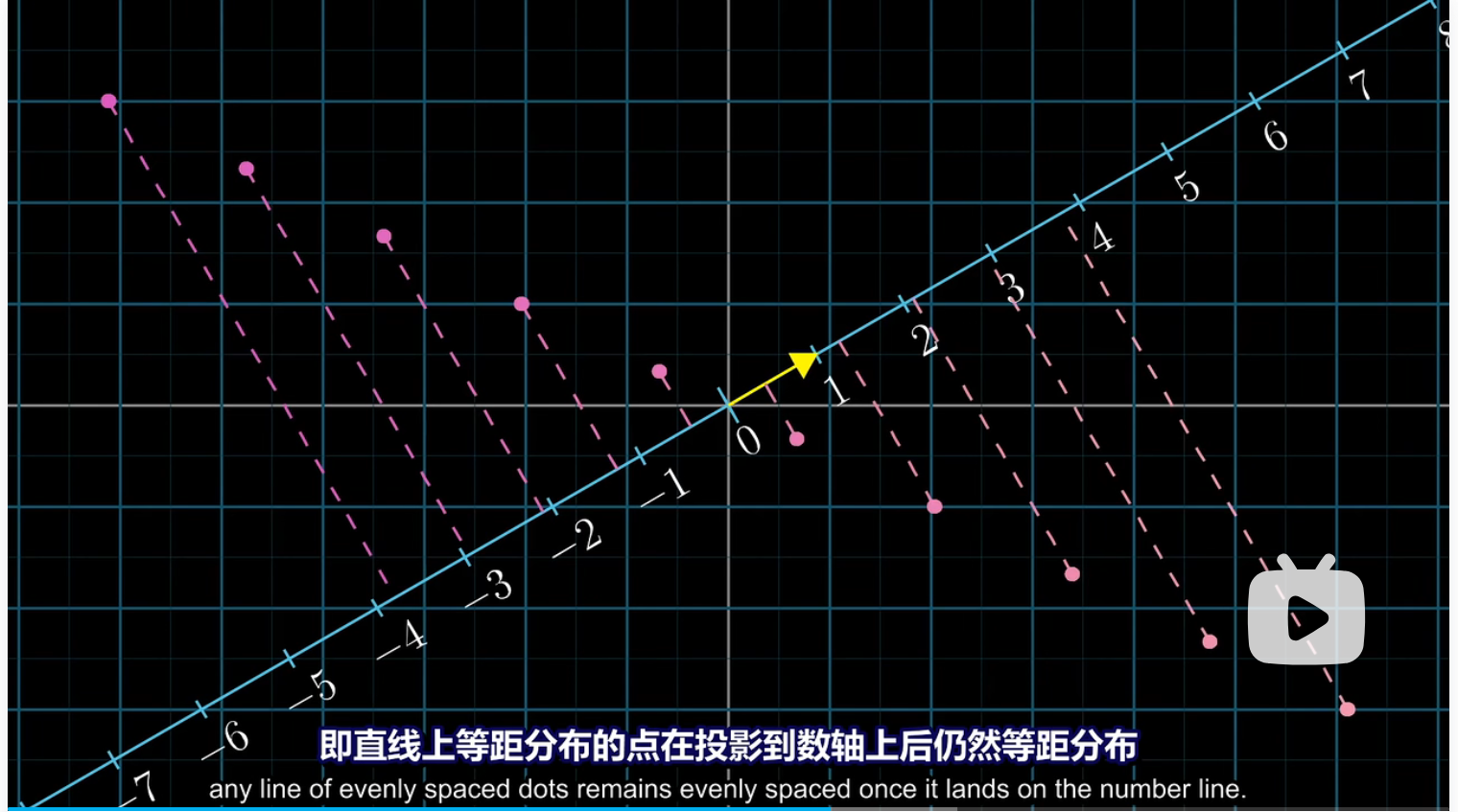
现在我们想要将一个空间中任意二维向量投影在这条数轴(数轴上只有数,没有方向)上,这个投影实际上就定义了一个从二维向量到数的函数,并且这个函数是线性的。
不过需要重申一下,前面提到的单位向量 $\hat u$ 是二维平面里的一个向量,只不过他正好落在这条数轴上 。根据这个投影,我们可以定义一个从二维向量到数的线性变换,即投影矩阵

为了找到这个投影矩阵,我们需要追踪 $\hat i,\hat j$ 变换后的坐标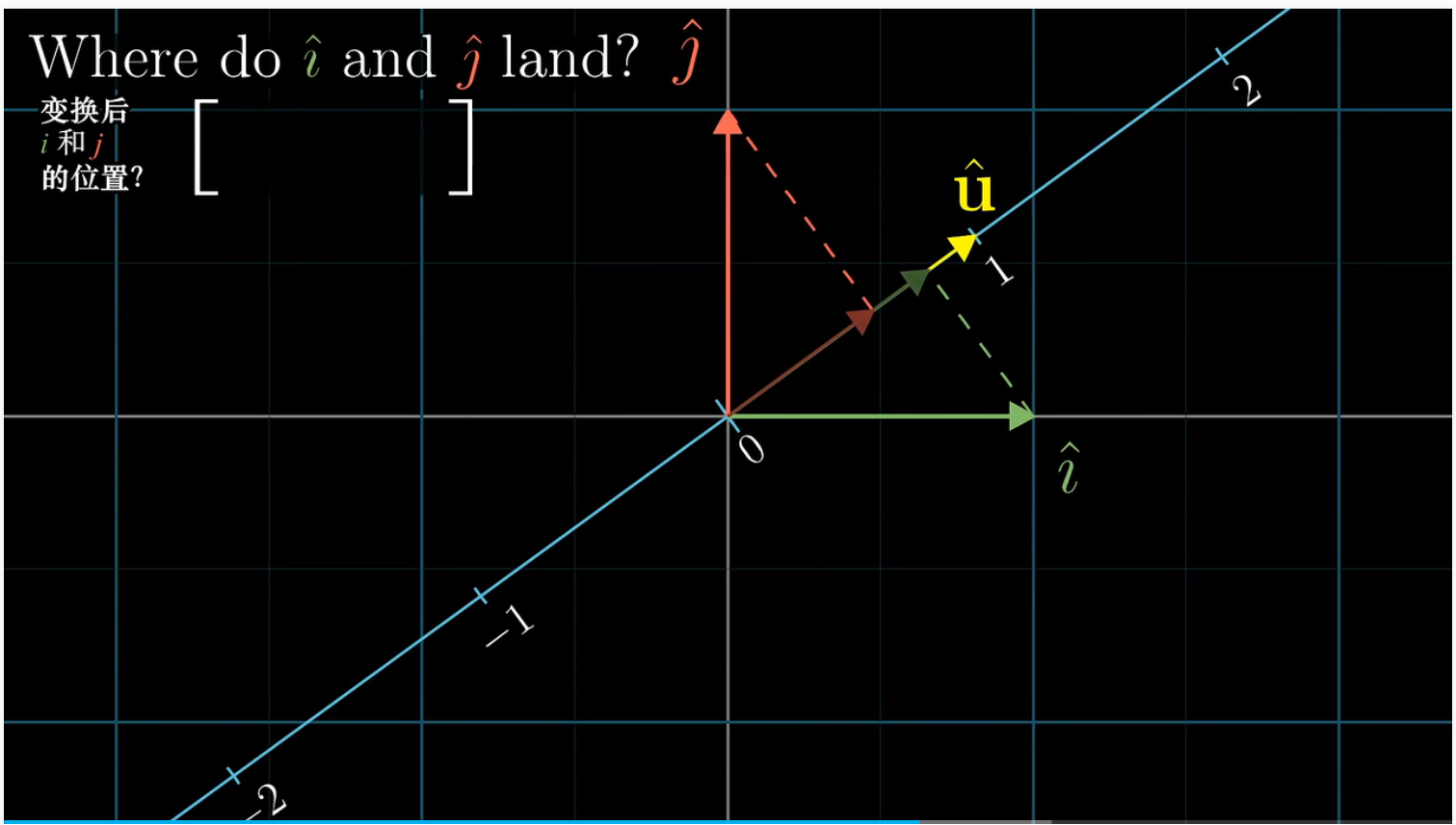
和前面证明点积与顺序无关一样,我们在 $\hat i,\hat u$ 中引入一条对称轴,

因此不难得出, $\hat i$ 在数轴上投射的数为 $\hat u_x$,同理 $\hat j$ 在数轴上投射的数为 $\hat u_y$,于是投影矩阵为 $[\hat u_x \ \hat y_y]$
因此空间中任意向量 $\left[ \begin{array}{l} x \ y \end{array} \right] $ 投影在这个数轴上的值,就是与这个投影矩阵相乘的结果: $\hat u_x \cdot x+\hat u_y\cdot y$。
而向量 $\left[ \begin{array}{l} x \ y \end{array} \right] $ 和向量 $\left[ \begin{array}{l} \hat u_x \ \hat u_y \end{array} \right] $ 的点积为也为 $\hat u_x \cdot x+\hat u_y\cdot y$
这就是为什么与单位向量的点积,就是将向量投影到单位向量所在的直线上所得到的投影长度。
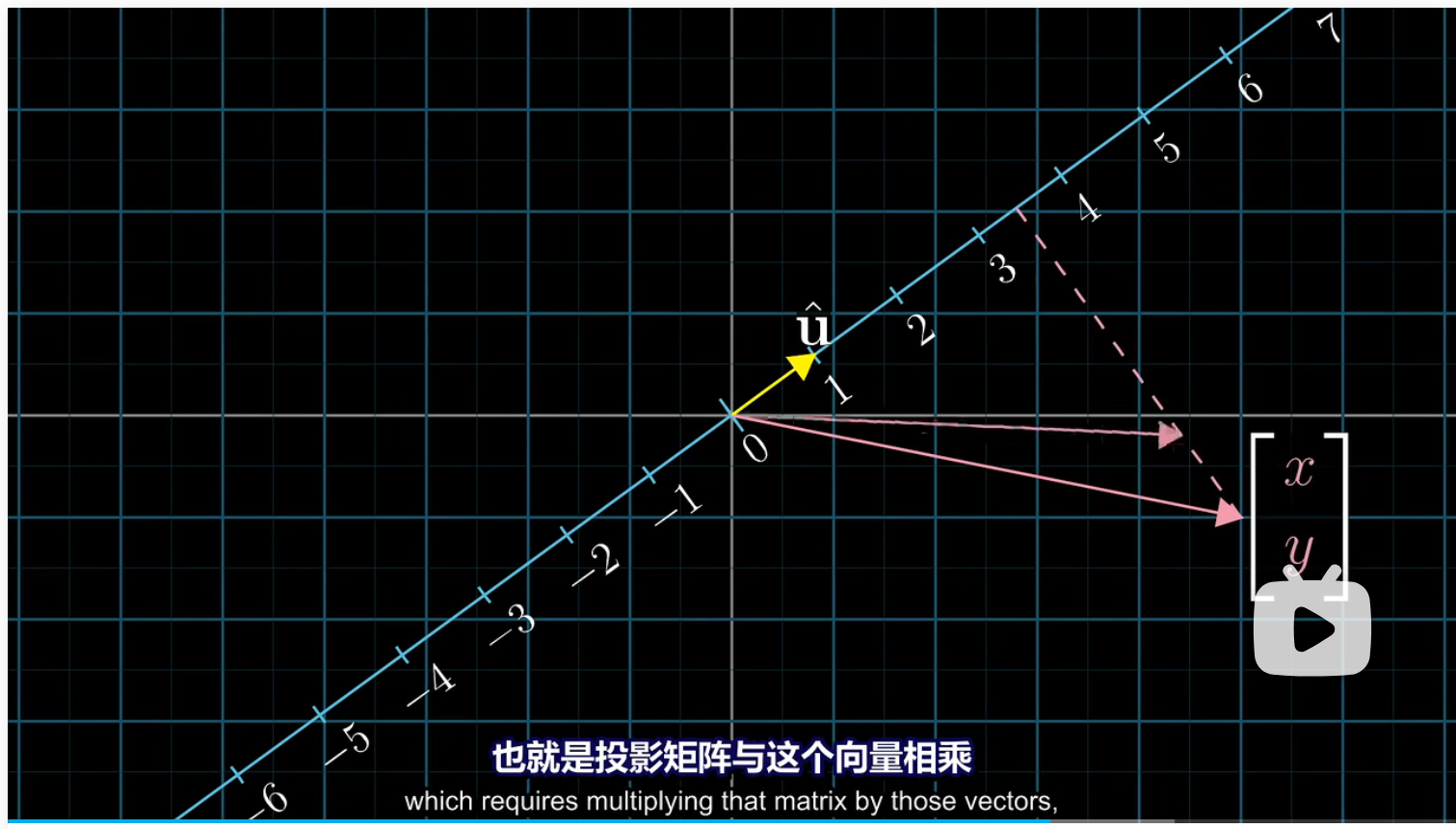
对于非单位向量而言,我们将单位向量进行缩放,与之相关的投影矩阵的每一项也会缩放,因此投影也会缩放。可以理解为,先投影,后根据向量与单位向量的比例进行缩放。
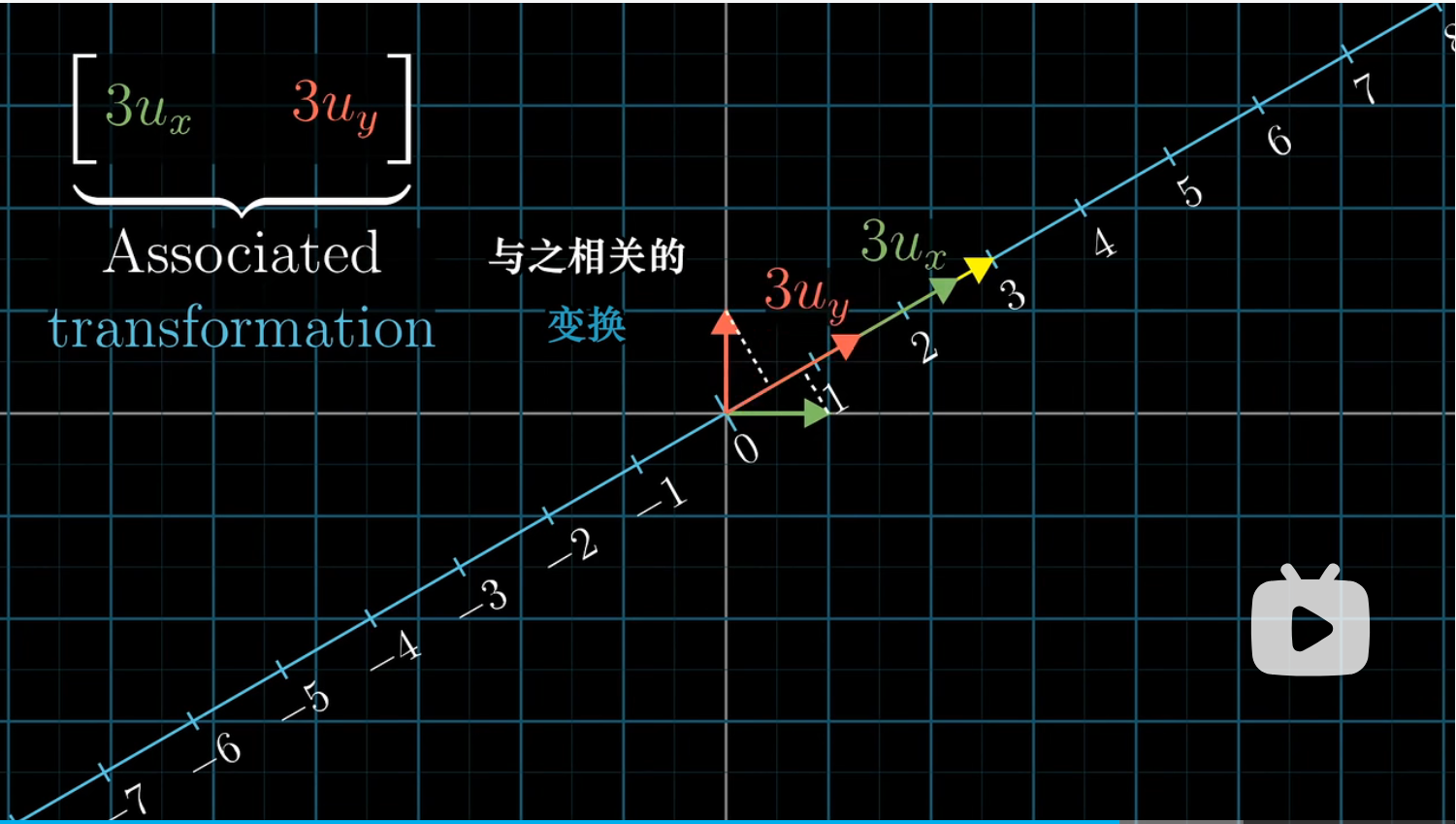
这就是为什么向量与给定非单位向量的点积可以解读为首先朝给定向量上投影,然后将投影的值与给定向量长度相乘。
这就是数学中 ”对偶性“ 的一个实例。

对于这一节的内容,我们可以说:一个向量的对偶是有它定义的线性变换。
而一个多维空间到一维空间的线性变换的对偶是多维空间中的某个特定向量。
08-1 叉积的标准介绍

提前说一点,目前这里描述的并不是严格的叉积。
假设我们有两个向量 $v,w$,考虑它们所张的平行四边形。那么两个向量的叉积,就等于这个平行四边形的面积
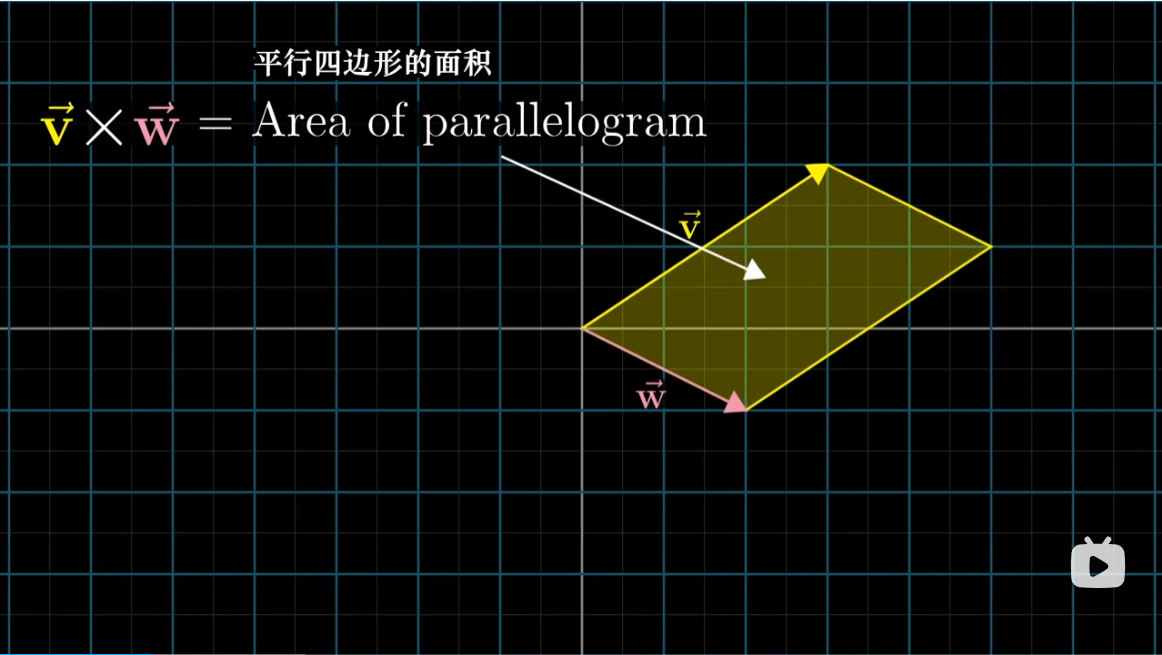
不过我们还要再考虑一个定向问题,大致来讲如果 $v$ 在 $w$ 的右边,那么 $v \times w$ 为正,值等于平行四边形的面积。这里也可以用右手定则,右手按顺序穿过 $v,w$,如果大拇指指向上方则为正,上图中的叉积则为负。
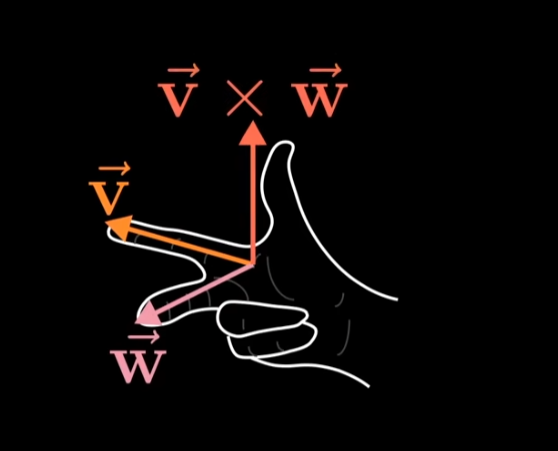
因此,叉积的顺序会影响结果的正负,即 $v \times w = - w \times v$
而平行四边的面积怎么计算呢?行列式在这里就起作用了。并且如果按照顺序将向量插入矩阵,计算出来的行列式的正负也满足叉积规则。
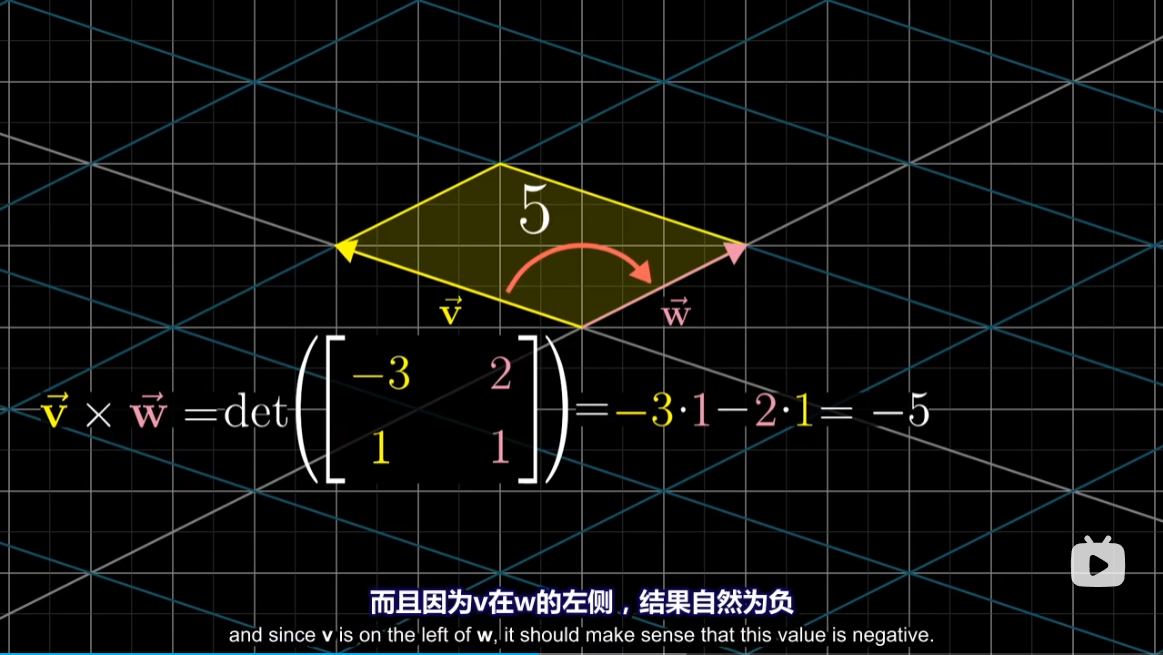
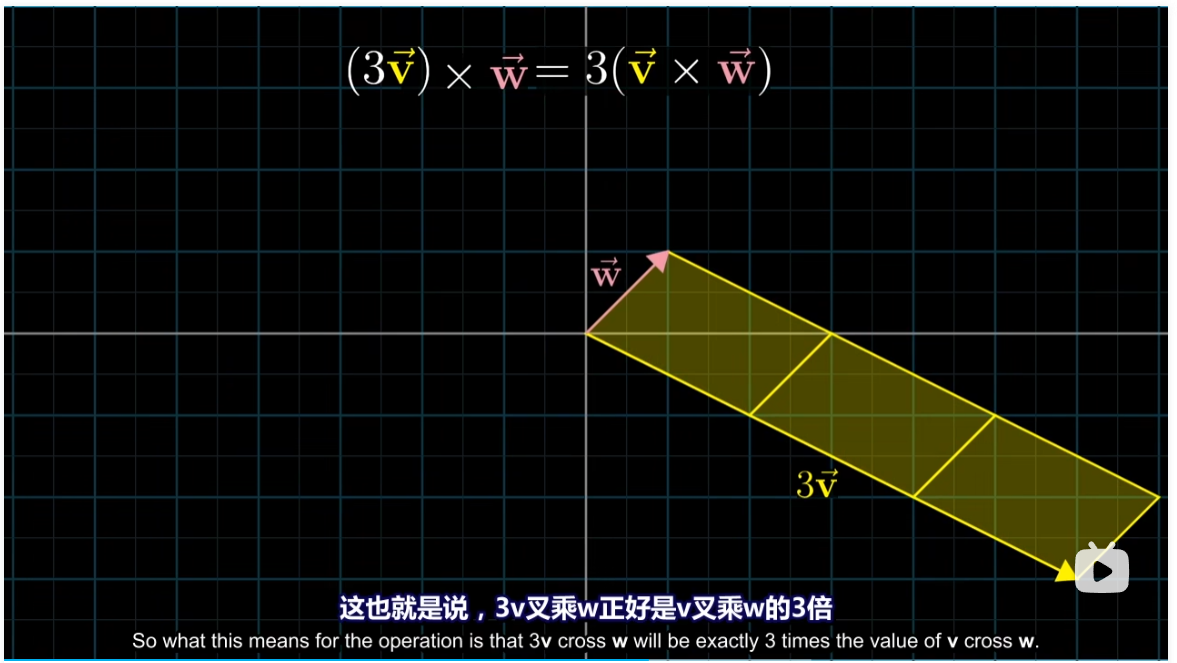
此时我们在脑海中想象,在长度不变的情况下,如果两个向量更接近垂直,他们的叉积(绝对值)就更大。如果放大其中一个向量,那么平行四边形的面积也会跟着放大
但严格意义上讲,这并不是叉积。真正的叉积是通过两个三维向量生成一个新的三维向量。
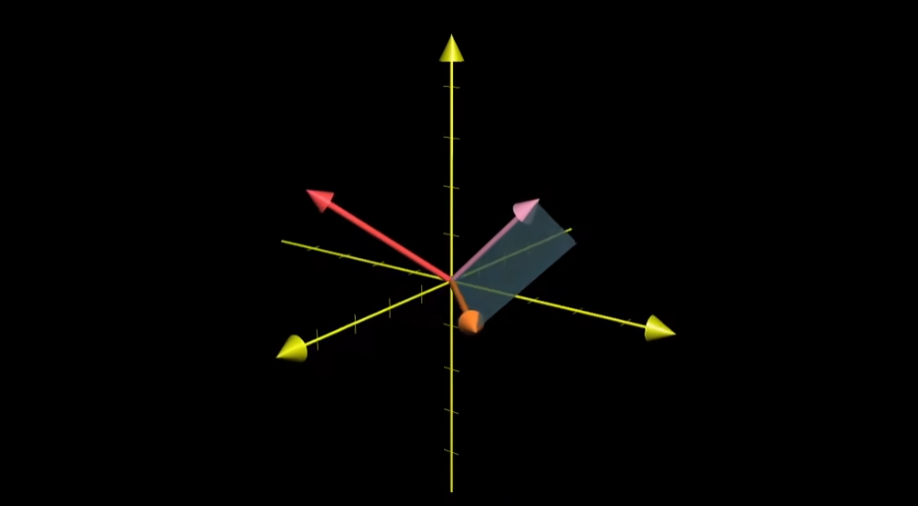
现在我们仍然考虑两个向量围成的平行四边形,假设这个平行四边形的面积是 2.5;而根据之前我们说叉积的结果是一个向量,这个向量的长度就是平行四边形的面积,在这里也就是 2.5;而这个向量的方向与平行四边形所在的面垂直。具体指向哪边,也可以根据我们前面提到的右手定则判断。
而对于更一般的情况,叉积的结果向量可以由以下公式计算得出
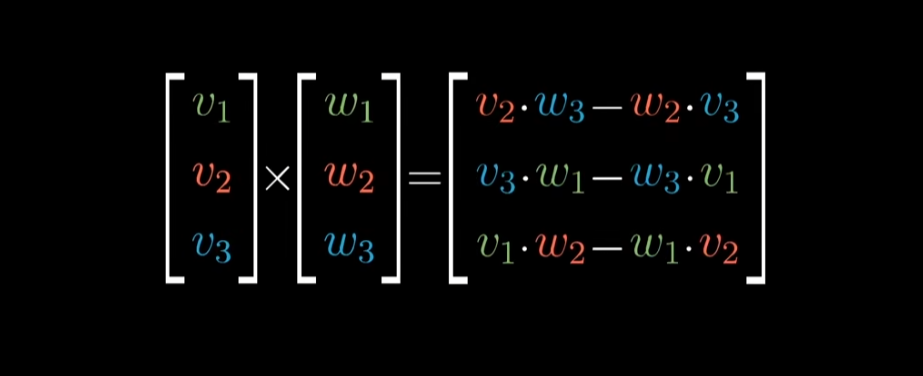
为了方便记忆它可以由一个三阶行列式代替,不过奇怪的东西就出现了。

通过上述计算,我们得到三个数,他们分别为叉积结果向量的坐标。这个向量的长度等于 $v,w$ 所确定的平行四边形的面积,且方向同时与 $v,w$ 所在平面垂直,并满足右手定则。

但第一列的基向量意味着什么呢?这里又需要引入我们上一节介绍的对偶性的思想。不过这一部分不在线性代数的本质中,它的重要性在于让我们了解叉积所得向量的几何意义。
sagemath
1 | # a 和 b 的叉积 |
08-2 以线性变换的眼光看叉积

在我们已经掌握了一些预备知识后,我们打算以线性变换的眼光看叉积。

前面我们提到,当我们看到一个多维空间到数轴的线性变换时,它都与那个空间中的唯一一个向量对应。也就是说应用线性变换和与这个向量点乘等价。这个向量被称为变换的对偶向量(Dual Vector)。
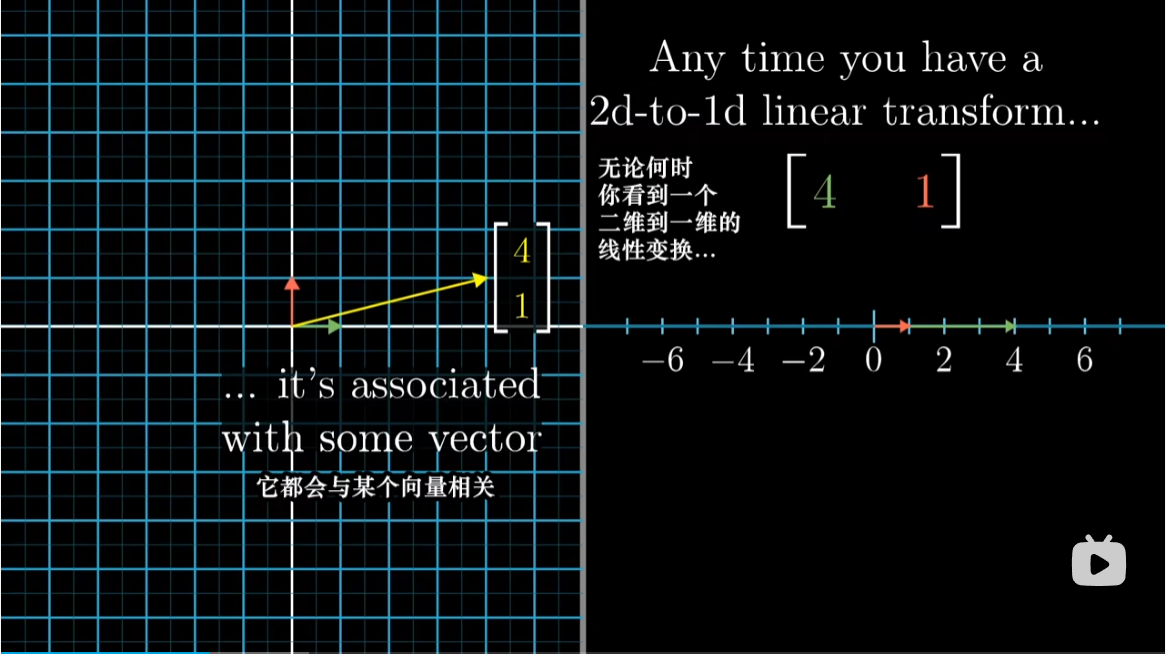
而这里的叉积,我们要定义一个从三维空间到数轴的特定线性变换,并且根据向量 $v,w$ 来定义。当我们找到这个变换与三维空间中的对偶向量关联时,这个对偶向量就会是 $v,w$ 的叉积。

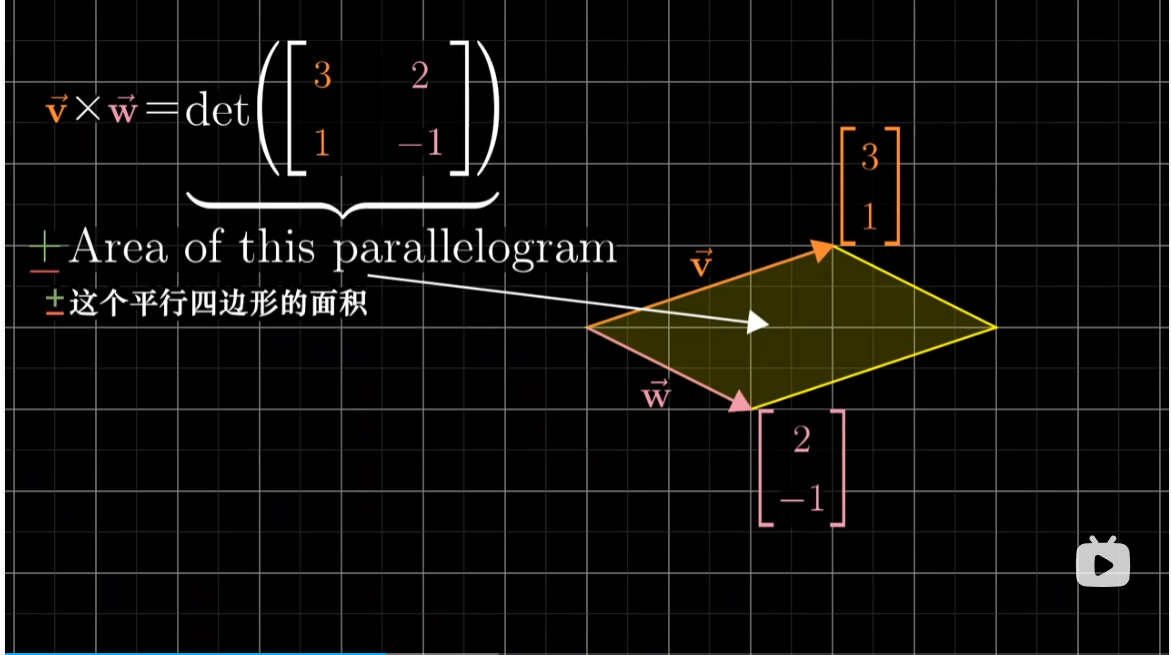
前面我们在二位平面中定义叉积时,只是使用了行列式。几何上说,行列式给出了两个向量张成的平行四边形的面积,正负则取决于两个向量的走向。
那么。当我们不知道三维向量的叉积并尝试往外推的时候,就可能会想应该是会涉及到三个向量 $u,v,w$,并将他们的坐标作为矩阵的列,然后计算这个矩阵的行列式。从几何上讲,这个行列式给出了三个向量张成的平行六面体的体积,外加一个正负号,取决于只三个向量是否满足右手定则。
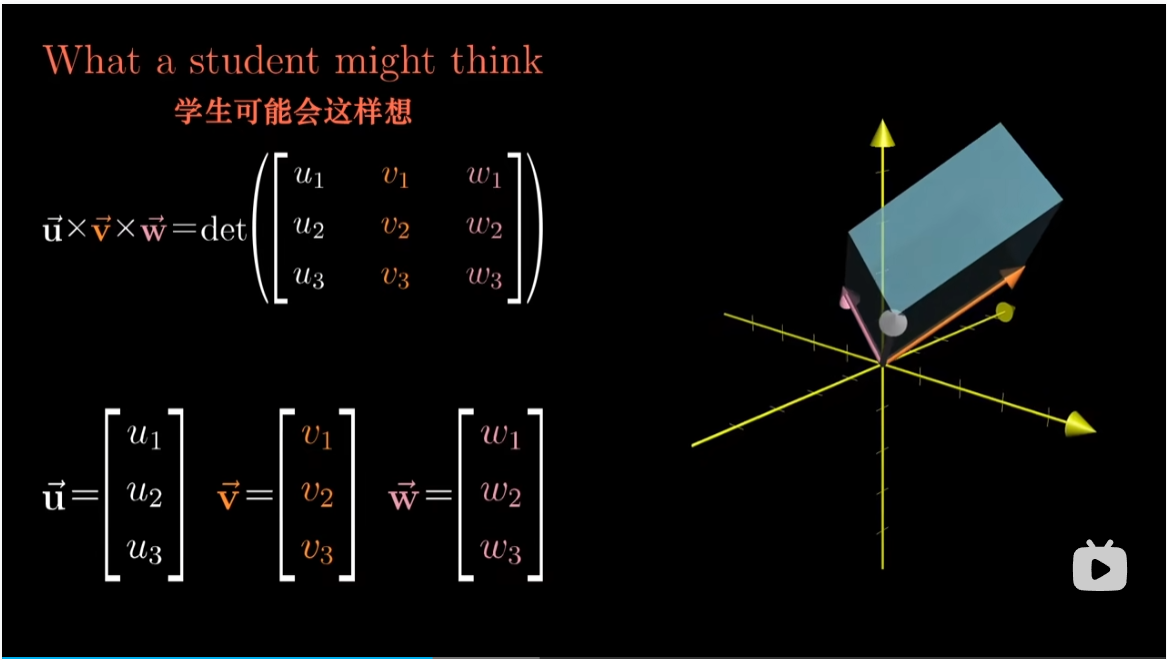
但我们知道这并不是真正的叉积,真正的三维向量的叉积是接受两个向量并输出一个向量,而不是输出一个数。但这个想法已经非常接近真实的叉积了。
我们将第一个向量 $u$ 看作是可变向量,比如 $(x,y,z)$,而 $v,w$ 保持不变。这样我们就拥有了一个从三维空间到数轴的函数了。

这个函数的几何意义是,对于任一输入的向量 $(x,y,z)$,我们考虑它和 $v,w$ 确定的平行六面体,得到他的体积,然后根据定向确定符号。
这个函数一个至关重要的性质在于它是线性的,然后我们开始引进对偶性的思想。首先,由于它是线性的,那么我们就知道它可以通过矩阵乘法来描述这个函数。具体来说,由于这个函数从三维空间到一维空间,那么就会存在一个 $1 \times 3$ 的矩阵来代表这个变换。

前面我们对偶性的整理思路:把多维空间到一维空间的线性变化对应于一个向量。就是把这个矩阵”立“起来,将整个变换看作是与这个特定向量的点积。
我们将这个特殊的三维向量设为 $p$
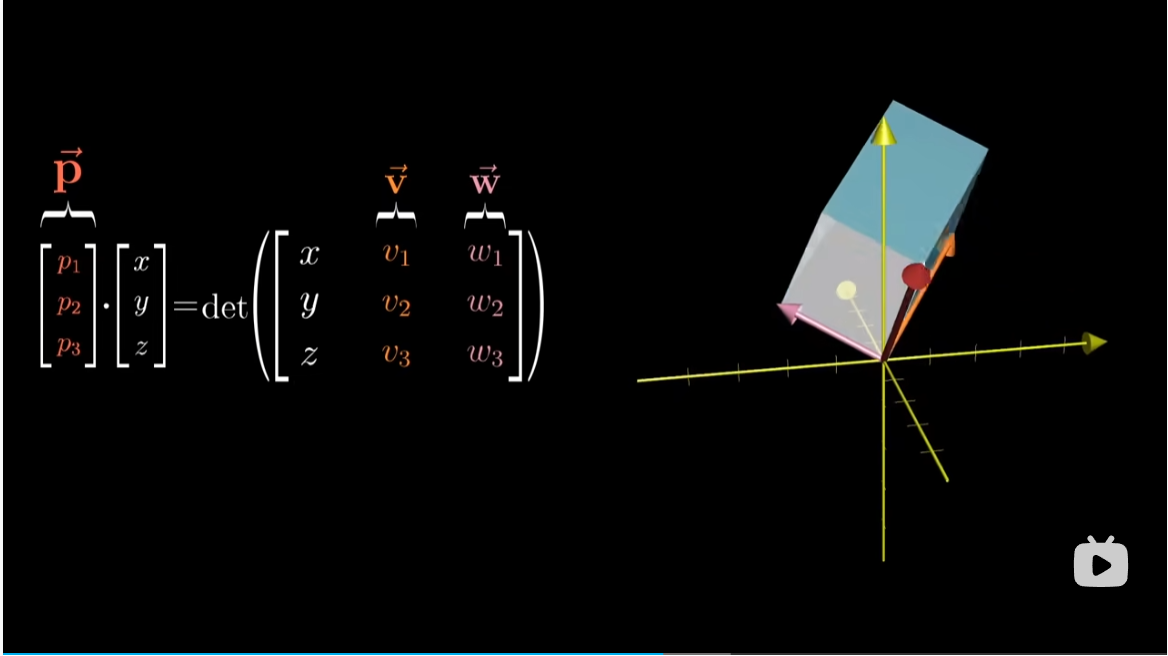
暂时考虑数值上的计算我们有
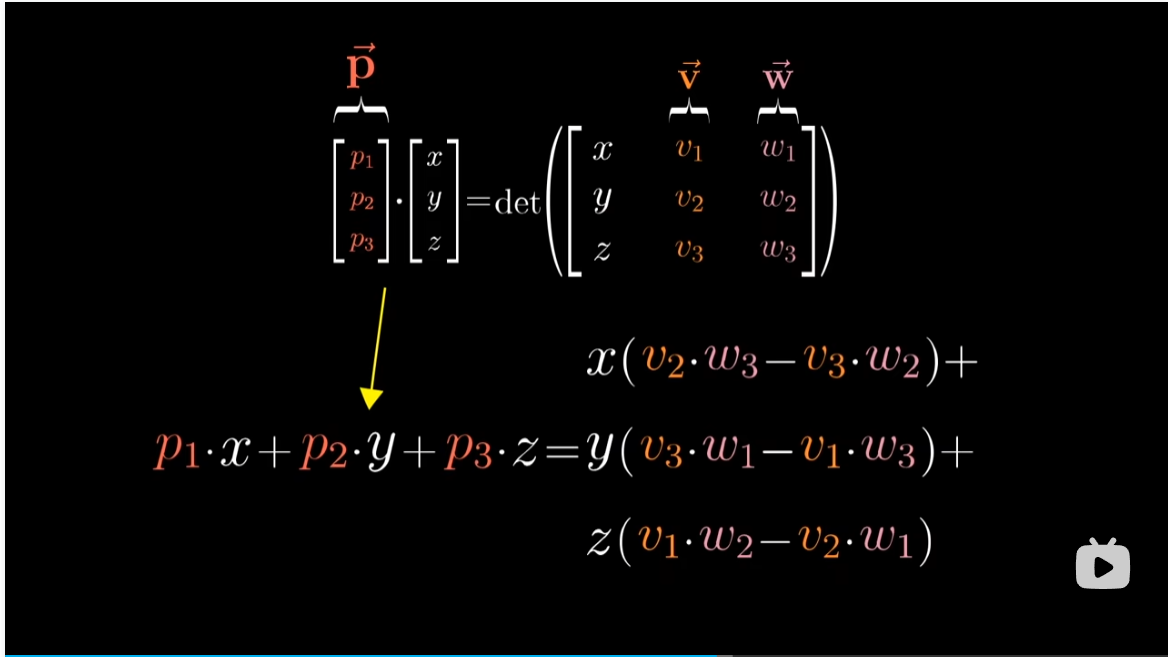
不难看出 $v,w$ 坐标的特定组合就是我们要找的 $p$ 向量。
这些奇怪的运算过程可以看作是以下问题的答案:当我们将 $p$ 和某个向量 $(x,y,z)$ 点乘时,所得结果等于一个 $3\times 3$ 矩阵的行列式,这个矩阵的第一列为 $(x,y,z)$,其余两列为 $v,w$ 的坐标。什么样的 $p$ 才能满足这一特殊的性质?

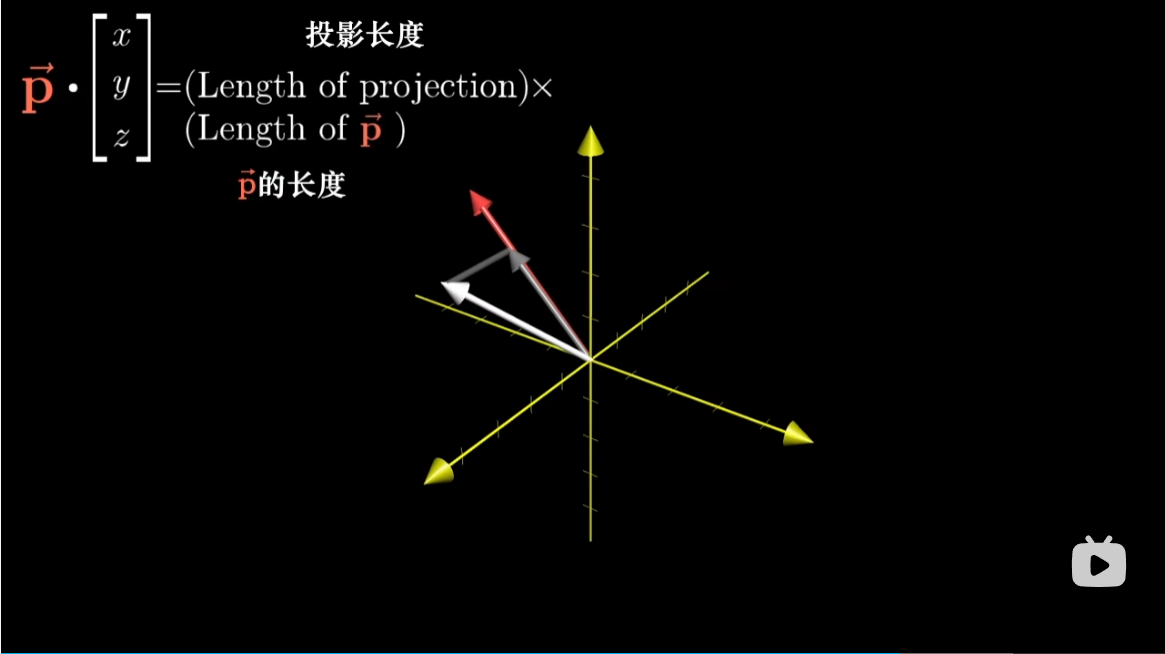
接下来是精彩部分,我们将从几何角度再次回答上述问题。当我们将 $p$ 和某个向量 $(x,y,z)$ 点乘时,所得结果等于一个由 $(x,y,z)$ 和 $v,w$ 确定的平行六面体的有向体积。什么样的向量 $p$ 才能满足这一特殊的性质?
记住,向量 $p$ 与其他向量的点积的几何解释,是将其他向量投影到 $p$ 上,然后将投影长度与 $p$ 的长度相乘
考虑到这一点,对于平行六面体的体积,我们首先获得 $v,w$ 确定的平行四面形的面积(这不就是前面我们”错误“定义的叉积么?),然后乘以向量 $(x,y,z)$ 在垂直于平行四边形方向上的分量。
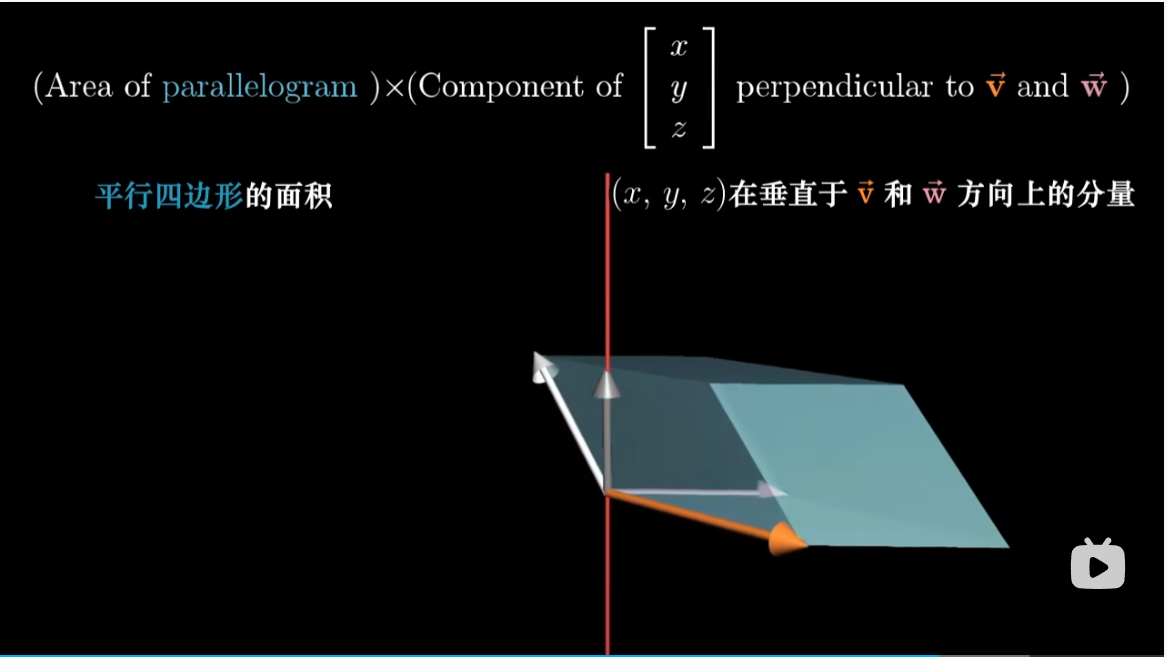
那么换句话说,我们找到的线性函数对于给定向量 $(x,y,z)$ 的作用:是将这个向量投影到垂直于 $v,w$ 的直线上,然后将投影长度与 $v,w$ 张成的平行四边形的面积相乘。
但是!这和垂直于 $v,w$ 且长度为平行四边形面积的向量 与 $(x,y,z)$ 点乘是同一回事。
更重要的是,如果选择了合适的向量方向,点积为正的情况就会与 $(x,y,z),v,w$ 满足右手定则的情况相吻合。
这意味我们找到了一个向量 $p$,使得 $p$ 与和某个向量 $(x,y,z)$ 点乘时,所得结果等于一个 $3 \times 3$ 矩阵的行列式。这个矩阵的三列分别为 $(x,y,z),v,w$.
因此我们前面计算得到的向量,必然在几何上与这个向量对应。这就是叉积的计算过程与几何解释有关联的根本原因。
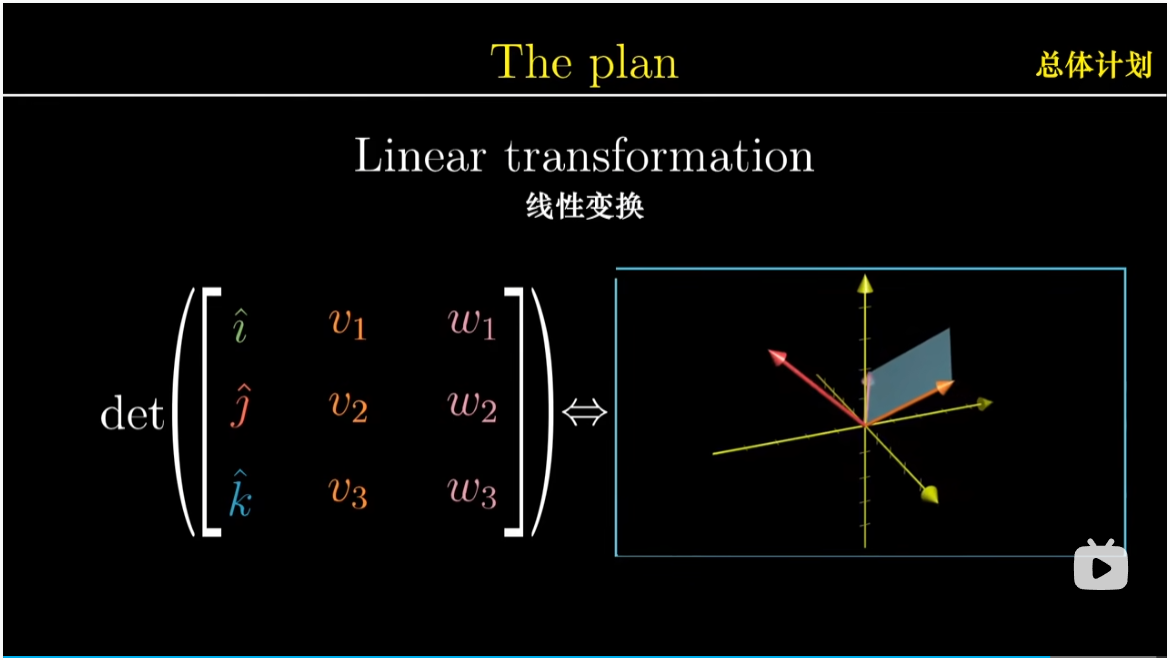
总结一下,我们首先定义了一个三维空间到数轴的线性变换,且是根据 $v,w$ 定义的。然后我们通过两种不同的方式考虑这个变换的对偶向量,即应用这个变换等价于与对偶向量点乘。
一方面,通过计算方法引入的技巧,即在矩阵第一列插入 $\hat i,\hat j,\hat k$,然后计算行列式
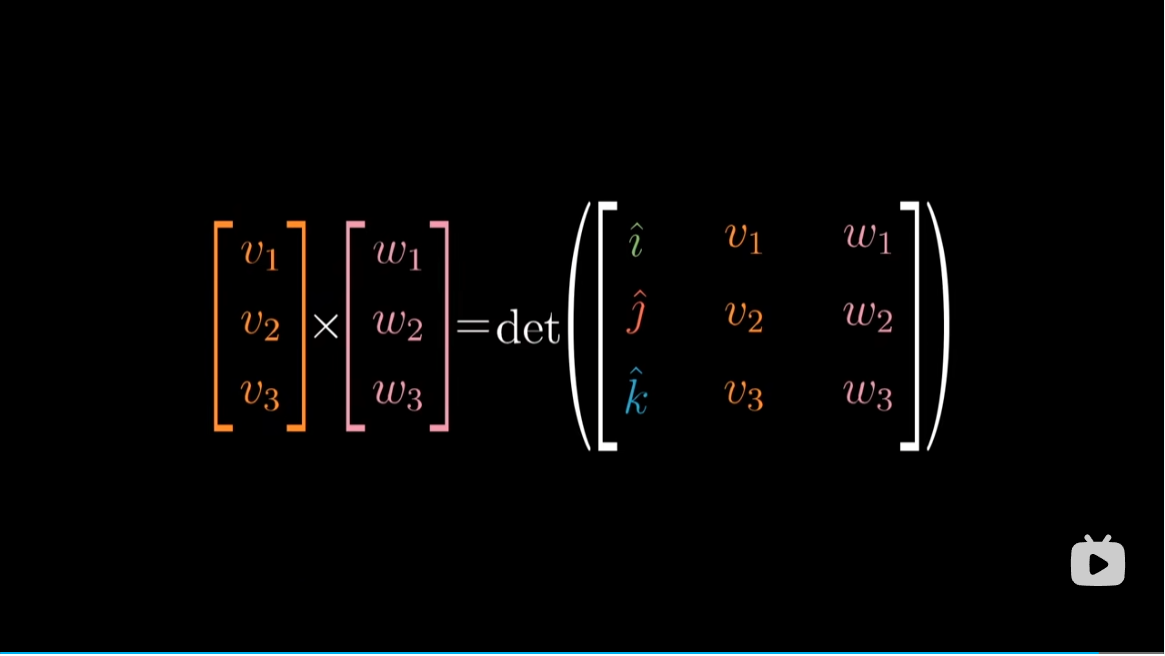
但是从几何角度,我们可以推断出这个对偶向量,必然与 $v,w$ 垂直,并且其长度与这两个向量张成的平行四边形的面积相同。
这两种方法给出了同一个变换的对偶向量,因此这两个向量也必然相同。
09 基变换
(建议这一集的视频反复观看)

在二维向量中,我们以更加线性代数的方法来描述坐标,即将坐标看作是伸缩向量的标量:我们可以将第一个坐标看作缩放 $\hat i$ 的标量,将第二个坐标看作是缩放 $\hat j$ 的标量。这里的 $\hat i$ 是指向右方且长度为 1 的向量; $\hat j$ 是指向正上方且长度为 1 的向量。这两个经过缩放向量的和就是坐标要描述的向量。
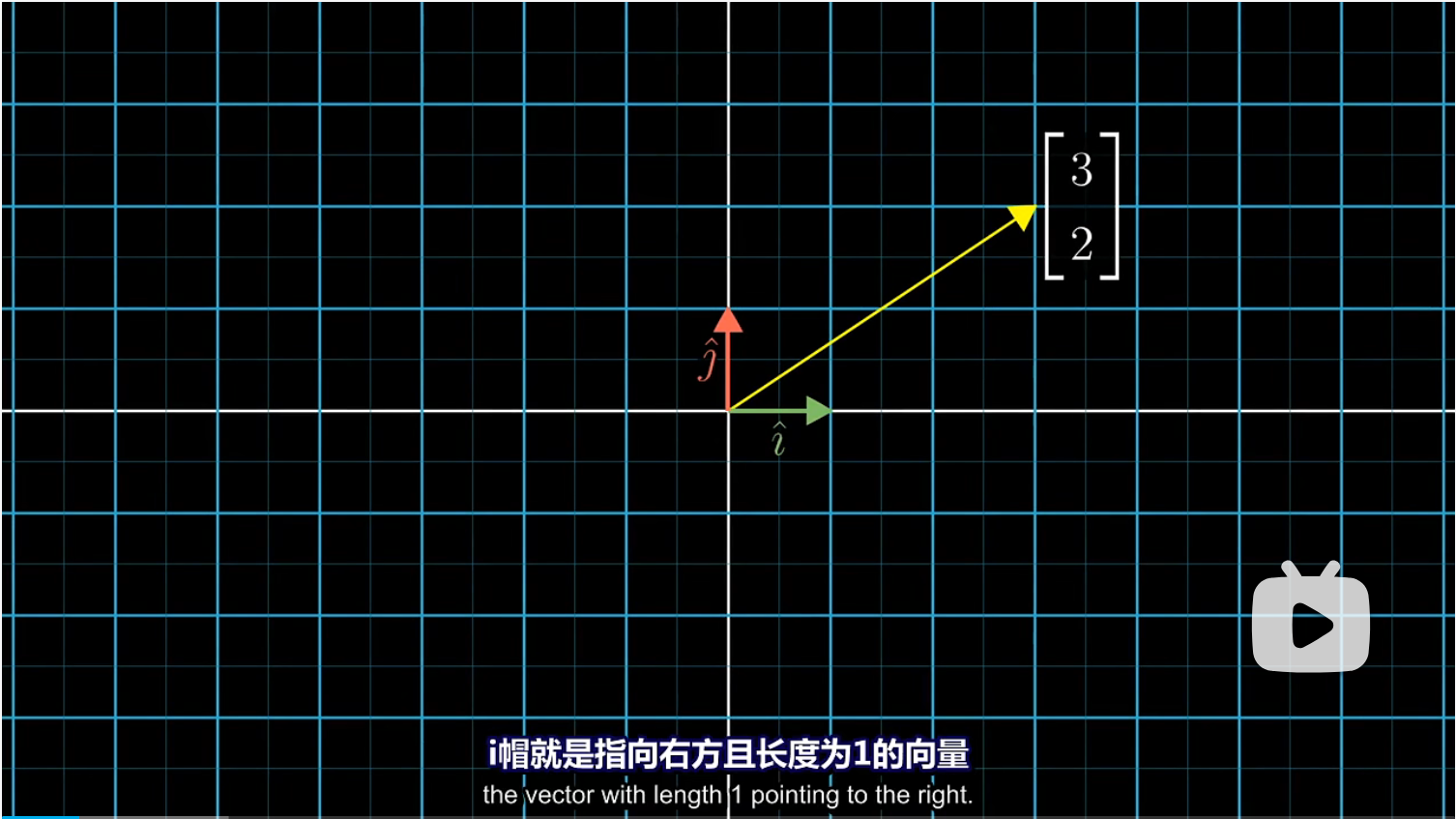
我们可以把上述内容作为一个坐标系中的隐含假设:第一个数字表示向右运动,第二个数字表示向上运动,单位长度的确切大小。而这一切都和 $\hat i,\hat j$ 的选取有密切联系。

因为这两个向量,正是坐标表示的标量缩放的对象。而发生在向量与一组数之间的任意一种转化,都被称为一个坐标系,而其中两个特殊的向量: $\hat i,\hat j$ ,被称为我们这个标准坐标系的基向量。
现在我们想讨论使用另一组基向量的思想。例如我们有一个朋友,詹妮弗,它使用的是另一组基向量 $b_1,b_2$
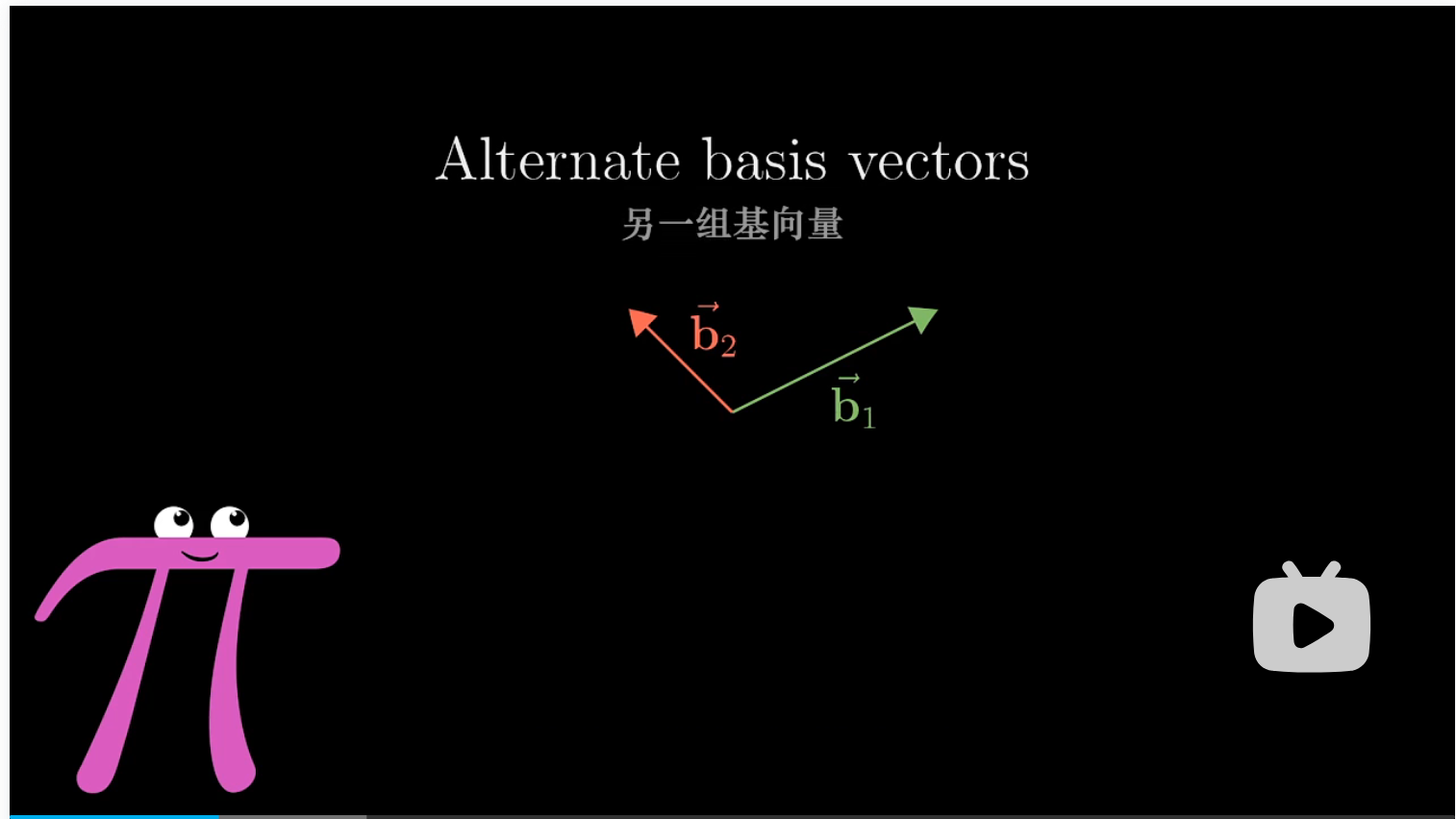
现在回到之前我们用 $\hat i,\hat j$ 表示的向量 $[3 \ 2]$,对于詹妮弗,她则会用 $[5/3 \ 1/3]$ 来描述,(之后我们会讨论如何计算这个新的坐标)

总之,无论何时詹妮弗用坐标来描述一个向量,都意味着她将第一个坐标乘以 $b_1$,第二个坐标乘以 $b_2$ ,然后将结果相加。不过由于基向量选取的不同,她最终得到向量,会和你我以为的向量完全不同。
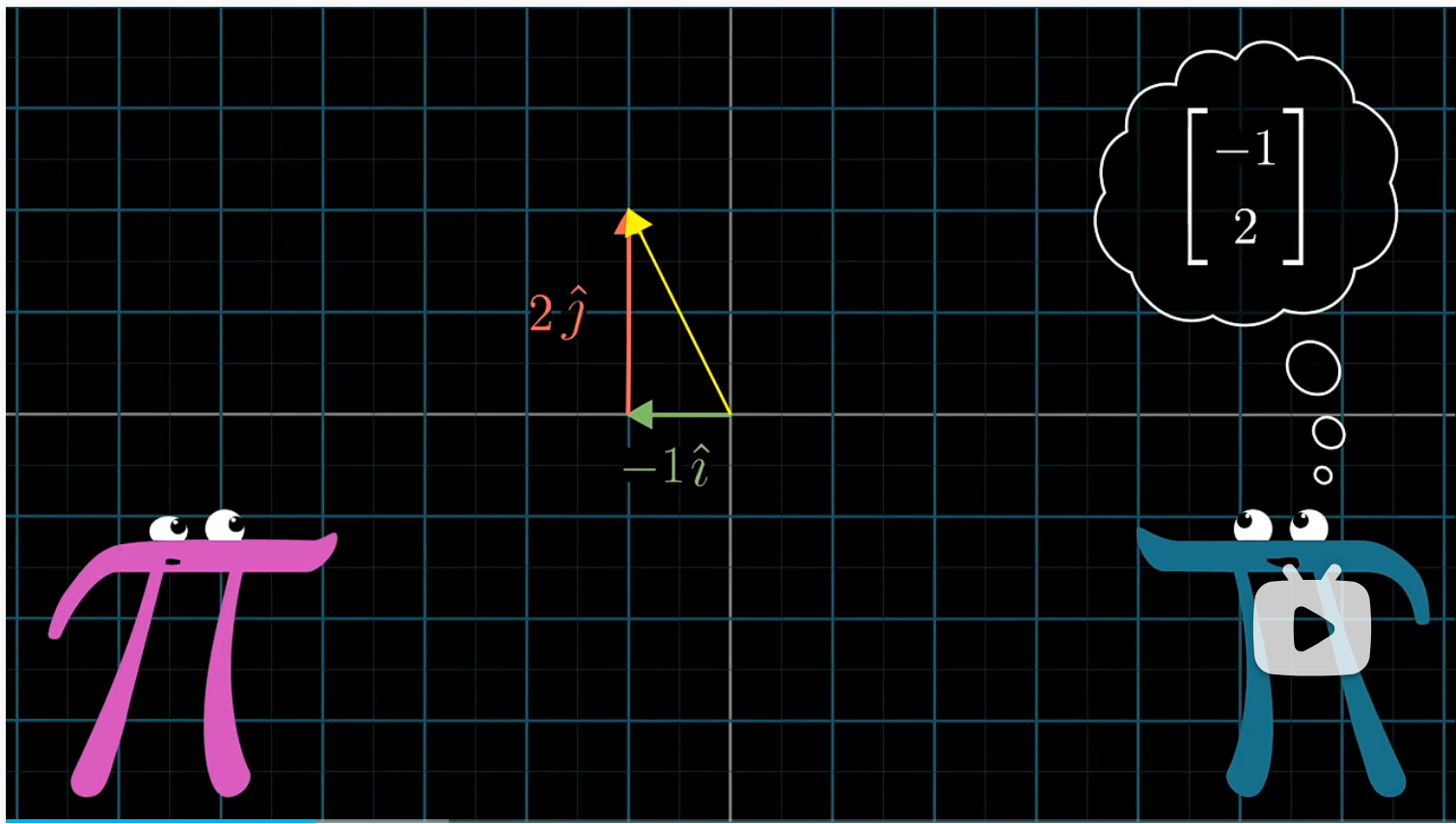
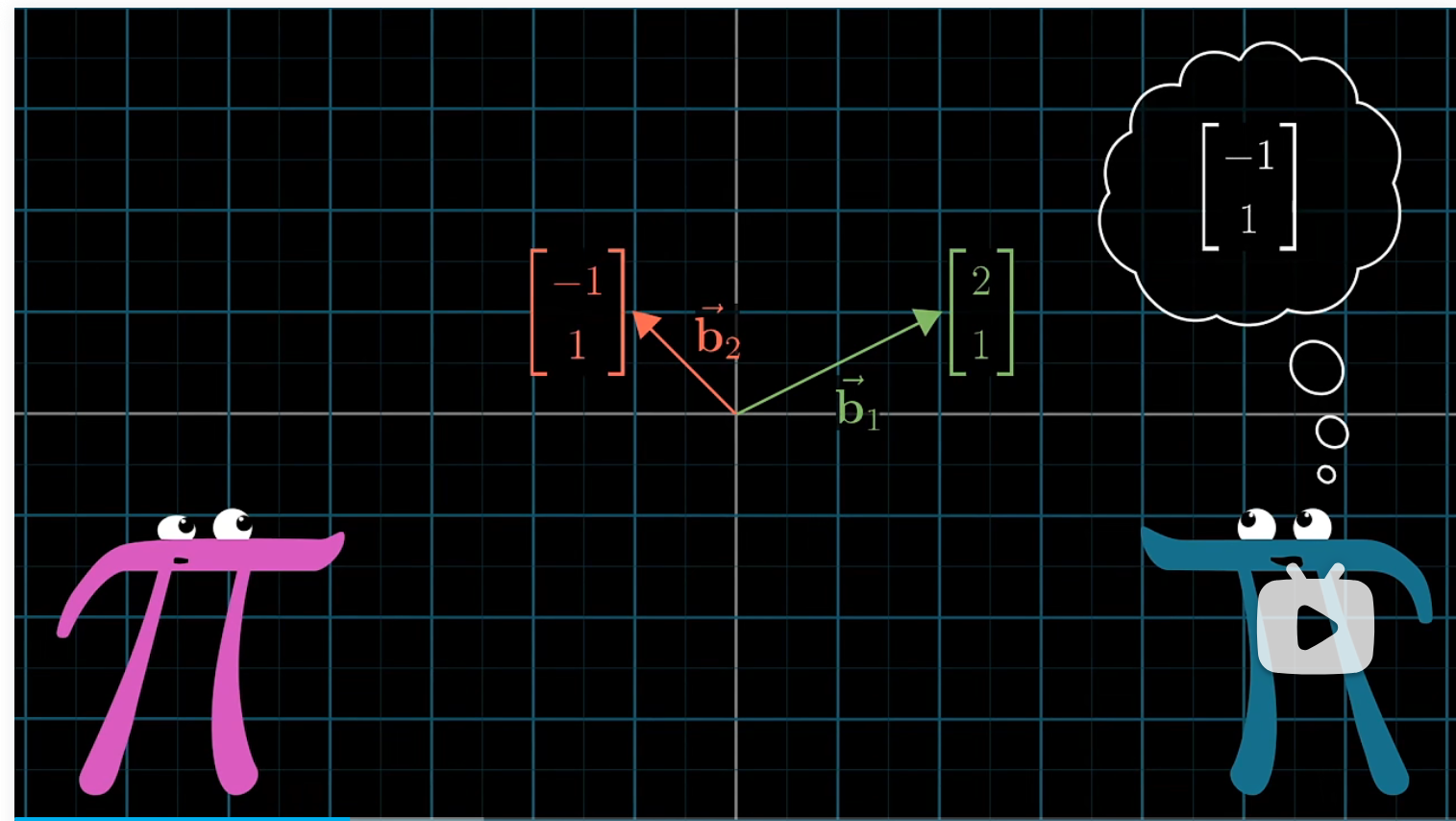
更确切的说,对于这里她的第一个基向量 $b_1$,我们会用坐标 $[2 \ 1]$ 来描述;而对于她的第二个基向量 $b_2$,我们则用 $[-1 \ 1]$ 来描述。
不过,在她的坐标系中,这两个向量的坐标是 $[1 \ 0],[0 \ 1]$,因为在她的”世界“, $b_1,b_2$ 是基向量,即定义 $[1 \ 0],[0 \ 1]$ 的向量。
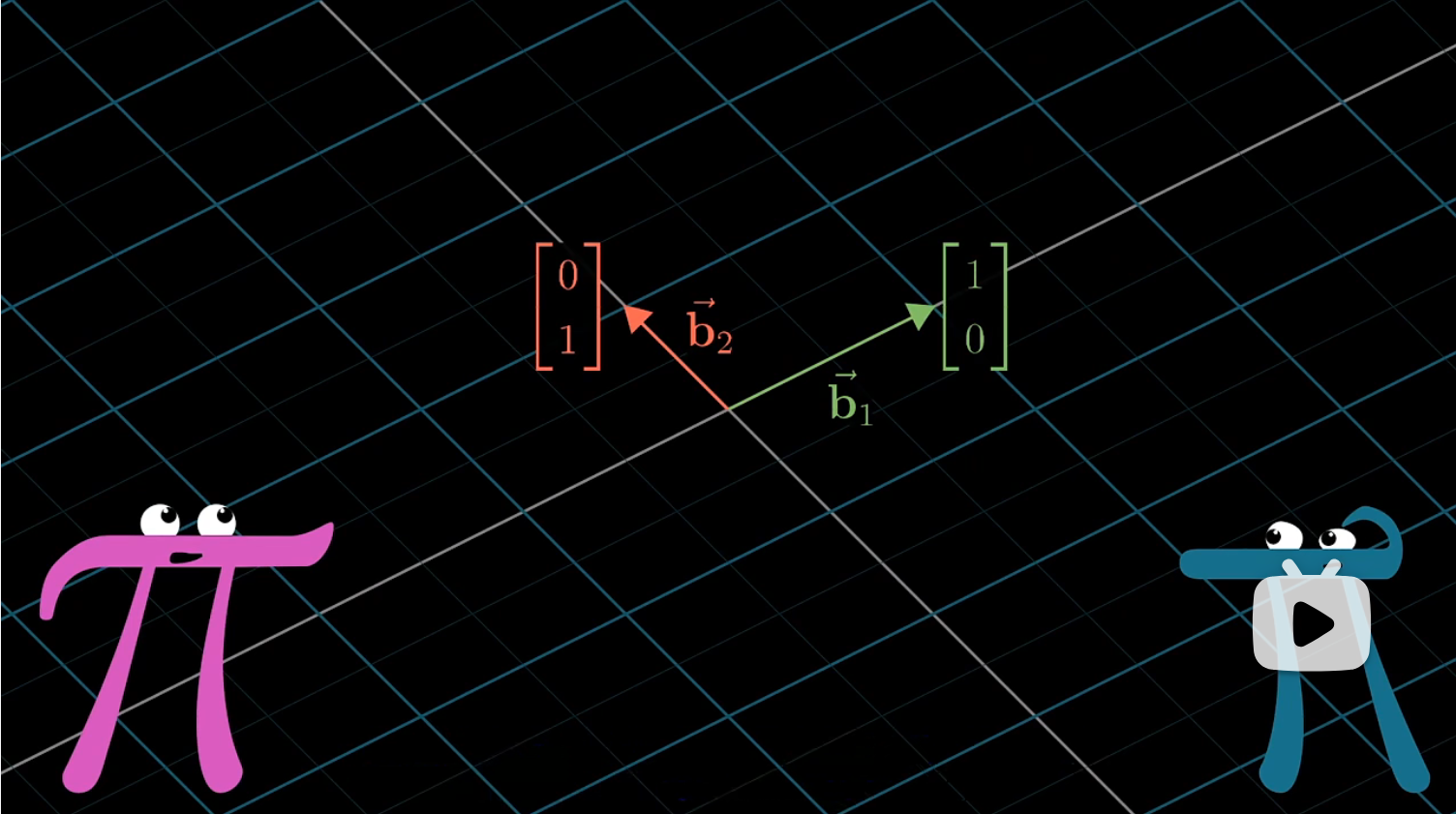
所以可以类比于詹妮弗和我们说的不是同一个语言。对于空间中同一个向量,詹妮弗和我们会用不同的语言是数字来描述它。

虽然空间中是不存在网格的,但是我们可以根据基向量来画出网格,这有助于理解坐标的含义。那么对于珍妮弗而言,她的网格大概就是这样
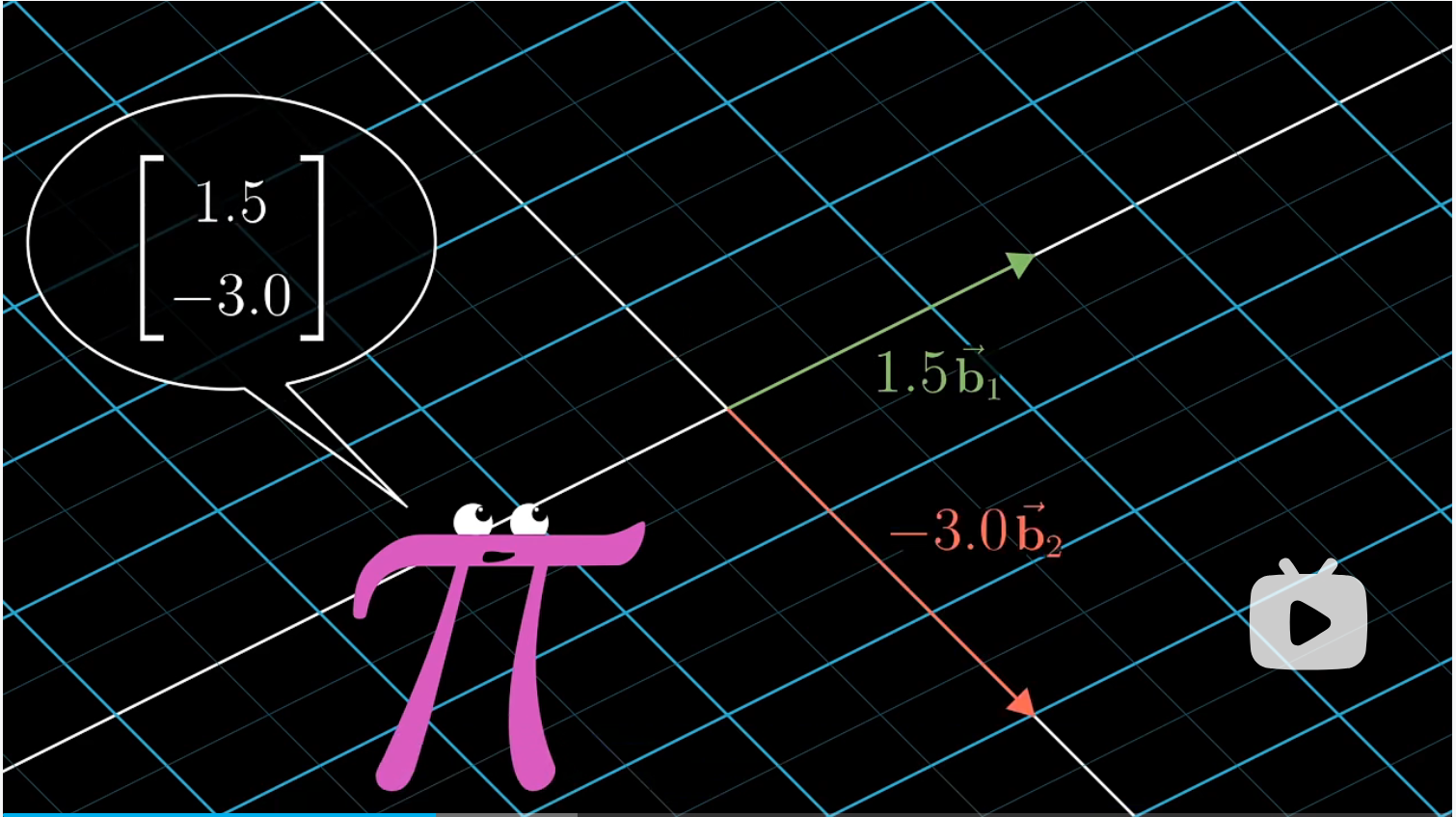
我们基于 $\hat i,\hat j$ 的网格则为

虽然大家的网格看起来不同(坐标轴的方向、网格间距)这依赖于对基的选择,但是在原点上是达成了共识。
那么在一切都构建完成了之后,一个很自然的问题是:如何在不同坐标系之间进行转化?
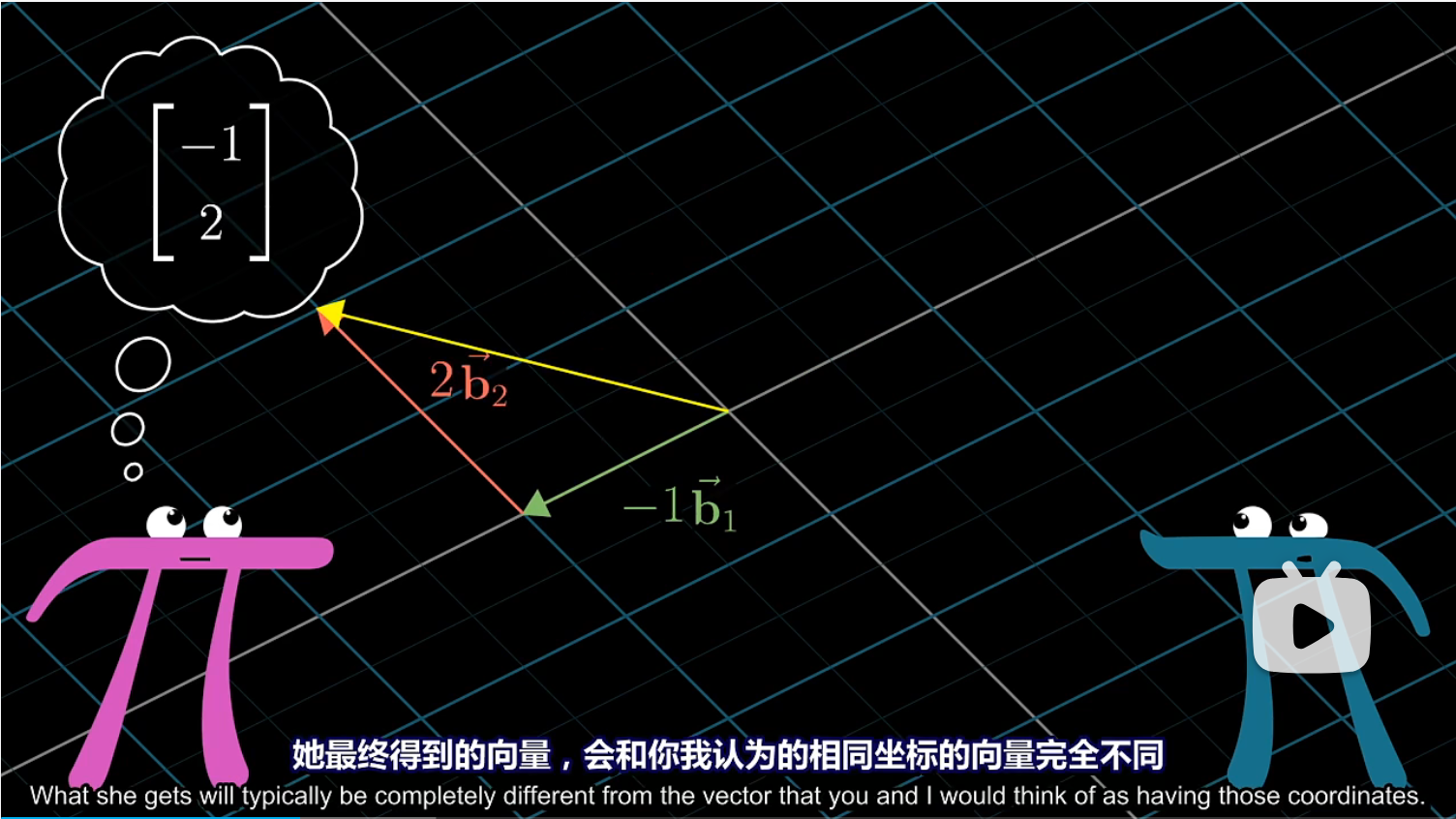
例如詹妮弗描述的 $[-1 \ 2]$ 向量,该如何在我们的坐标系中进行描述?
詹妮弗的 $[-1 \ 2]$ 意味着标量 $-1$ 乘以 $b_1$ 加上标量 $2$ 乘以 $b_2$。而在我们看来,$b_1$ 的坐标是 $[2 \ 1]$,$b_2$ 的坐标是 $[-1 \ 1]$。因此我们可以直接计算 $-b_1+2b_2=[-4 \ 1]$ ,这就是在我们坐标系中,詹妮弗认为的坐标为 $[-1 \ 2]$ 的向量。
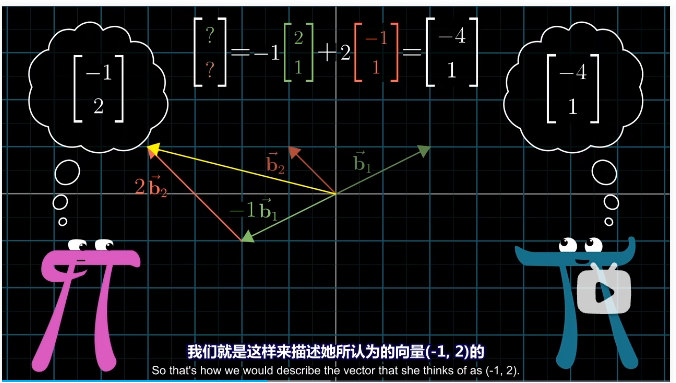
这里发生的,也就是某个向量的特定坐标与詹妮弗的基向量数乘在求和。这看起来不眼熟么?这就是矩阵向量乘法。
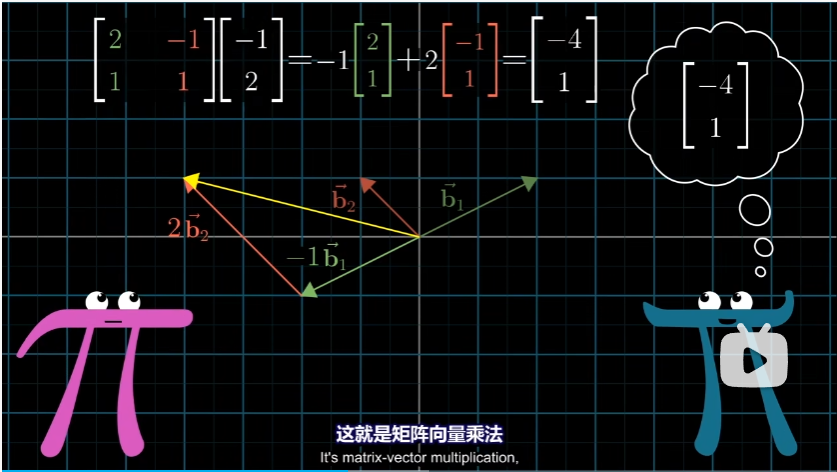
这个矩阵的列代表的是用我们的语言,表达的是詹妮弗的基向量。并且如果我们将这个矩阵理解成一个特定的线性变换,那么这个矩阵就是将我们的基向量 $\hat i,\hat j $ 变换为詹妮弗的基向量 $b_1,b_2$。
让我们再想一下,对向量 $[-1 \ 2]$ 应用变换是什么意思?在变换之前,我们所想的向量是我们的基向量的一种特定线性组合:$-1$ 乘以 $\hat i$ 加上 $2$ 乘以 $\hat j$。而线性变换的一个重要特性就在于,变换后的向量仍旧是相同的线性组合,不过是用新的基向量:$-1$ 乘以变换后的 $\hat i$ 加上 $2$ 乘以变换后的 $\hat j$。因此这个矩阵的变换效果,就是将我们对詹妮弗的向量的误解,变换为她提到的真正向量。(将她的向量,用我们的坐标系表示)
不过这个过程看起来似乎是颠倒的:从几何上说,这个矩阵将我们的网格变换为詹妮弗的网格;但是从数值上说,这是将她的语言转化为我们的语言。
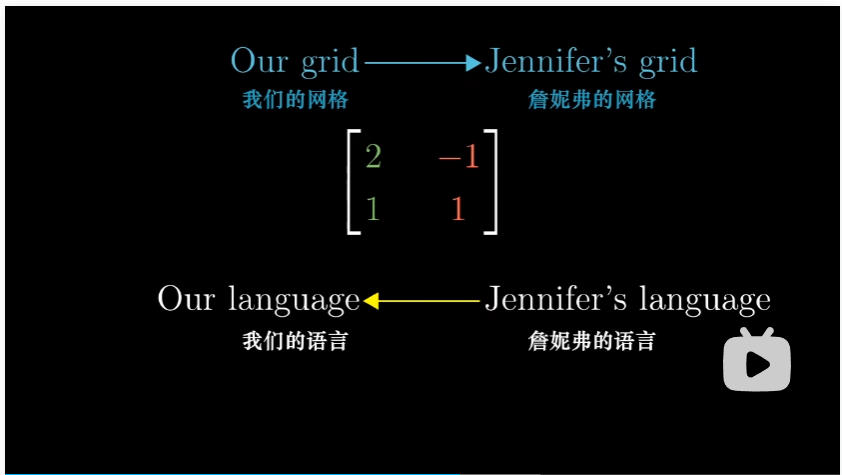
那么相反方向是如何的呢?假如在我们的坐标中有一个 $[3 \ 2]$ 的向量,我们如何计算出它在詹妮弗的坐标系中的坐标为 $[5/3 \ 1/3 ]$ 呢?
之前那个矩阵是将詹妮弗的语言转化为我们的语言,因此想要将我们的语言转化为詹妮弗的语言,我们只需要找到前面那个矩阵的逆矩阵就可以了。
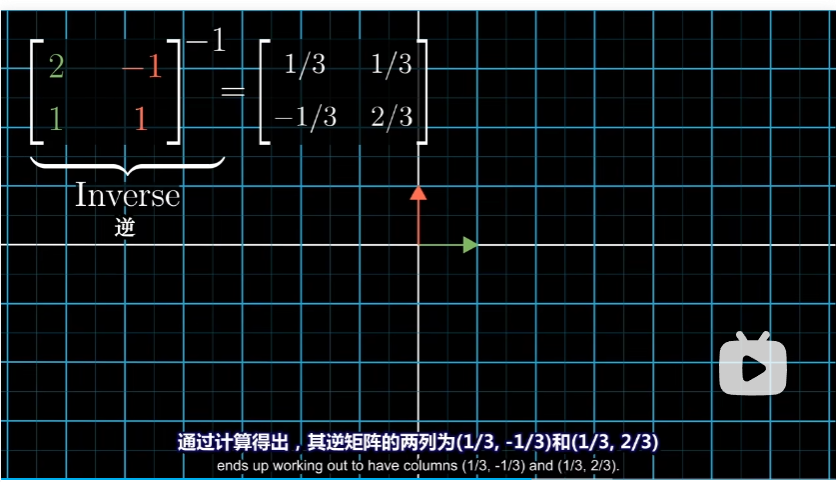
我们只需要将这个矩阵乘以我们的 $[3 \ 2]$,就能够得到该向量在詹妮弗坐标系中的描述。

总而言之,以上就是如何在坐标系之间对单个向量的描述进行相互转化。
接下来我们考虑某个线性变换在不同坐标系之间描述的转化。比如逆时针旋转90°。我们是通过跟踪 $\hat i,\hat j$ 的去向,随后确定与之对应的矩阵。这也意味着矩阵的表示和我们对基向量的选择密切相关。

那么詹妮弗如何描述同样的逆时针旋转90°呢?同样使用上述矩阵么?并不可以,上述矩阵表述的是 $\hat i,\hat j$ 的去向,詹妮弗想要知道的是 $b_1,b_2$ 的去向,并用她的语言来描述。【重点来了,可以留意一下图片中矩阵颜色的变化】
首先,我们从詹妮弗语言描述的任一向量出发,然后我们使用基变换矩阵,将这一向量转化为用我们的语言描述。

然后将所得结果左乘线性变换矩阵
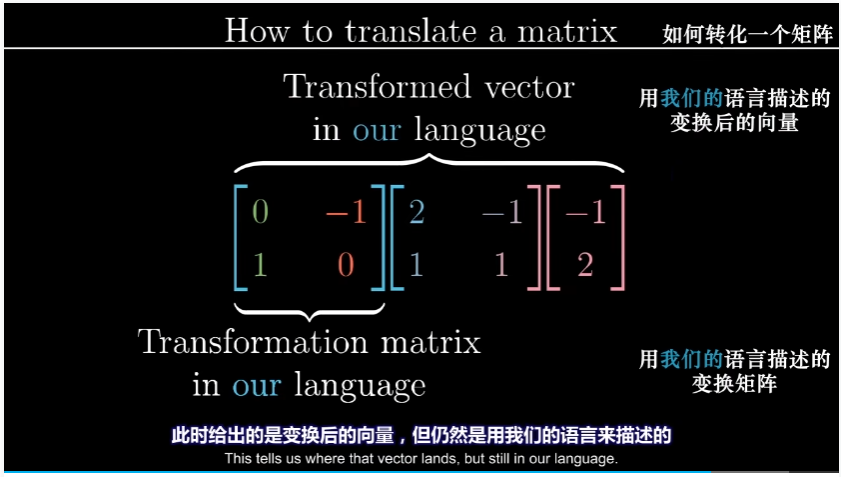
最后,我们要像之前一样将所得结果左乘基变换矩阵的逆,将我们的语言转回詹妮弗的语言

由于我们能对詹妮弗坐标系下的任意向量都做同样的事,于是可以记为 $v$,而左边三个矩阵的复合给出的就是用詹妮弗语言描述的线性变换矩阵:它接受用詹妮弗语言描述的向量,并输出詹妮弗语言描述的变换后的向量。

总的来说,每当我们看到这样的一个表达式:$A^{-1} MA$,这就暗示着数学上的转移作用。中间的矩阵代表一种我们所见的变换,而外侧两个矩阵则起着转移作用,也就是视角上的转化。三个矩阵复合仍然代表着同一个变换,(这里的例子就是它们都代表着逆时针旋转90°)只不过是从其他人的角度来看的。
至于为什么要关注坐标系的变换,下一节的特征值和特征向量将给出一个重要的实例。
10 特征向量与特征值

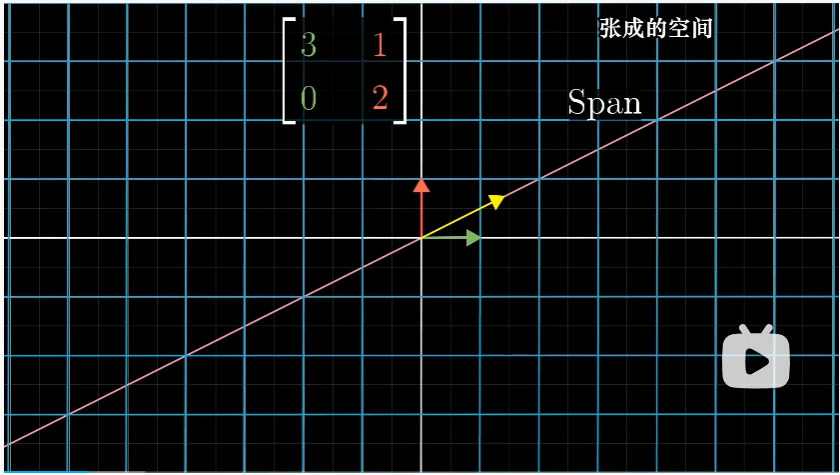
首先,考虑二维空间中的某个线性变换,

用矩阵来描述就是将 $\hat i,\hat j $ 分别作为列向量。
我们关注它对一个特定向量的作用,并且考虑这个向量张成的空间,也就是通过远点和向量尖端的直线
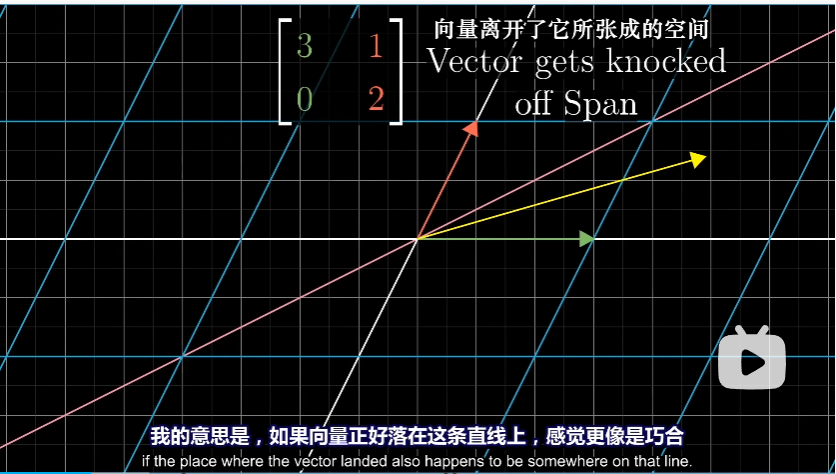
随后应用变换,我们发现,大部分向量在变换中都离开了其张成的空间
不过某些向量确实留在了其张成空间中,即意味着矩阵对他的作用仅仅是伸缩,如同标量一样
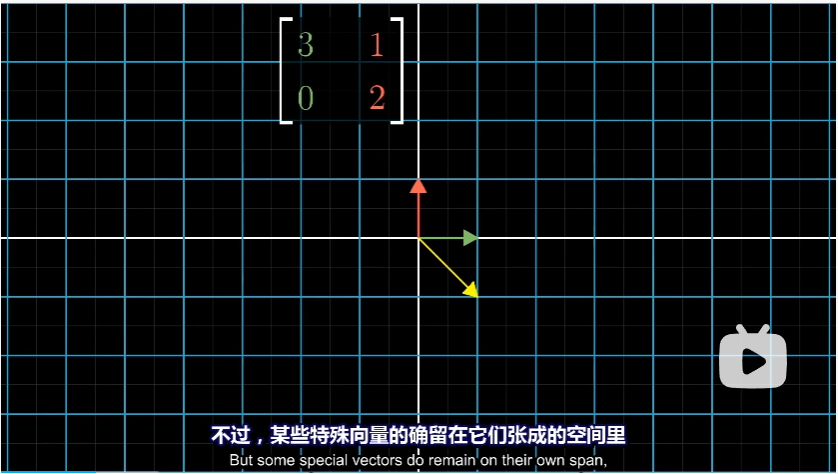
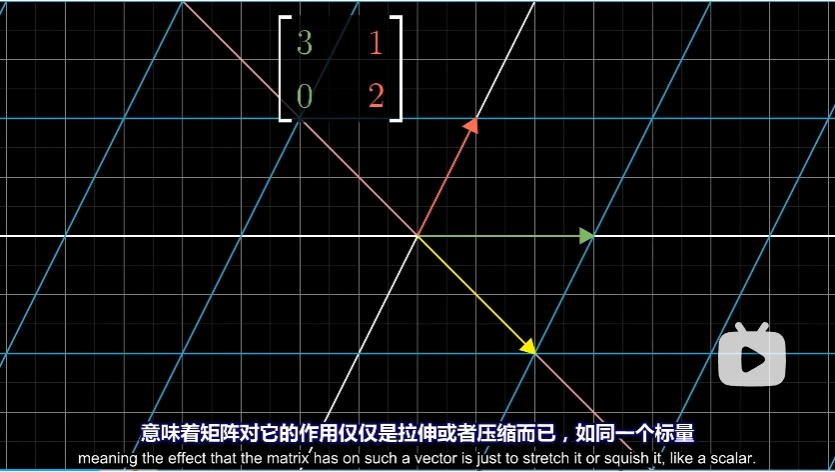
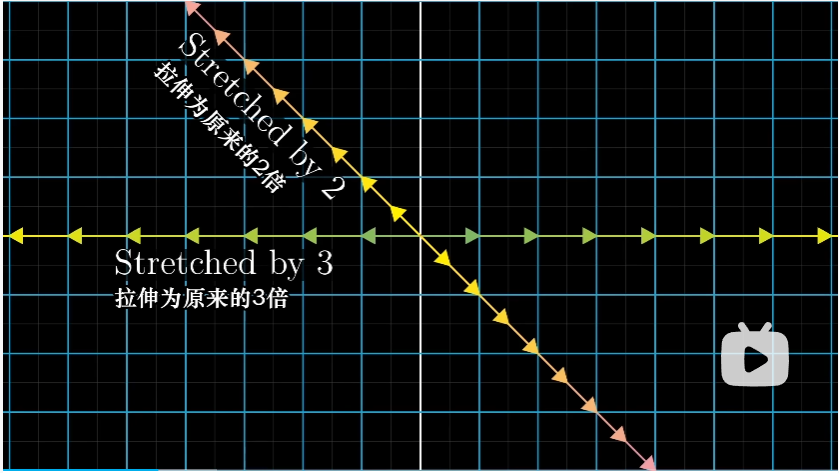
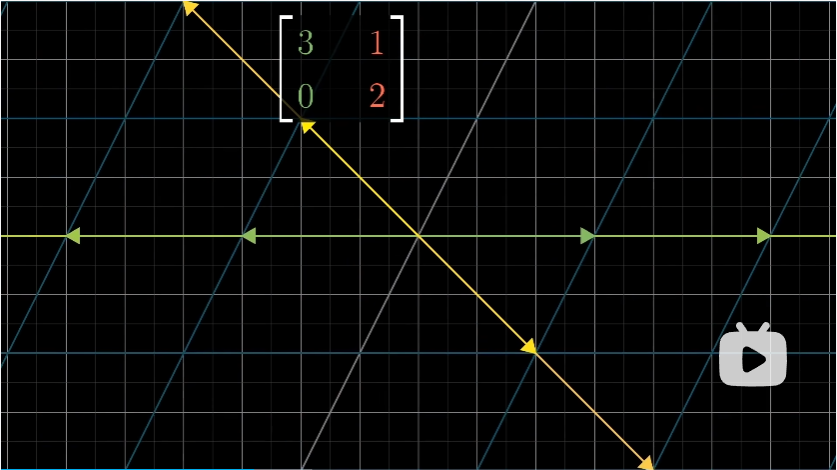
在上述例子中, $\hat i$ 也是这样一个特殊的向量。$\hat i$ 张成的空间是 $x$ 轴,而从图中(或者是根据矩阵的第一列)可以看出,$\hat i$ 变成了原来的 3 倍,且仍然留在 $x$ 轴上。根据线性变换的性质, $x$ 轴上其他向量变换后也仍然停留在 $x$ 轴上,长度变为原来 3 倍。
另一个略显隐蔽的向量 $[1 \ -1]$ 在变换后也停留在自己张成的空间中,最终被拉伸为原来的两倍。(可以从图中黄色的向量看出)同样的,根据线性变换的性质,这个空间中的其他向量变换后也仍然停留在空间中,长度变为原来 2 倍。
对于这个变换而言,上面就是所有拥有这一特殊性质的向量。
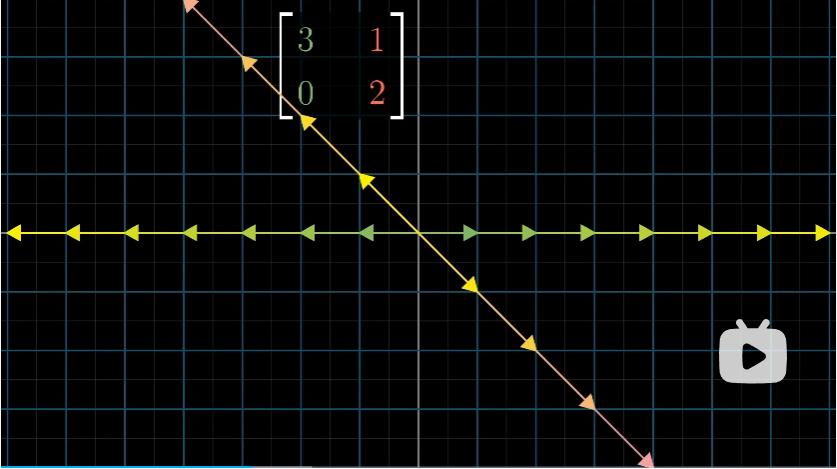
而任何其他向量,都有或多或少的旋转,从而离开原来张成的直线。
估计大伙都已经猜到了,这些特殊的向量,就被称为变换的“特征向量”,每个特征向量都有一个所属的值,被称为”特征值“,即衡量特征向量在变换中伸缩的比例。若拉伸值为正,则没什么特殊的地方,拉伸值为负,则代表对应特征向量发生了反向。
这为什么有用途而值得研究?我们可以考虑一个三维空间中的旋转。如果我们能够找到这个旋转的特征向量,那么我们找到的就是旋转轴
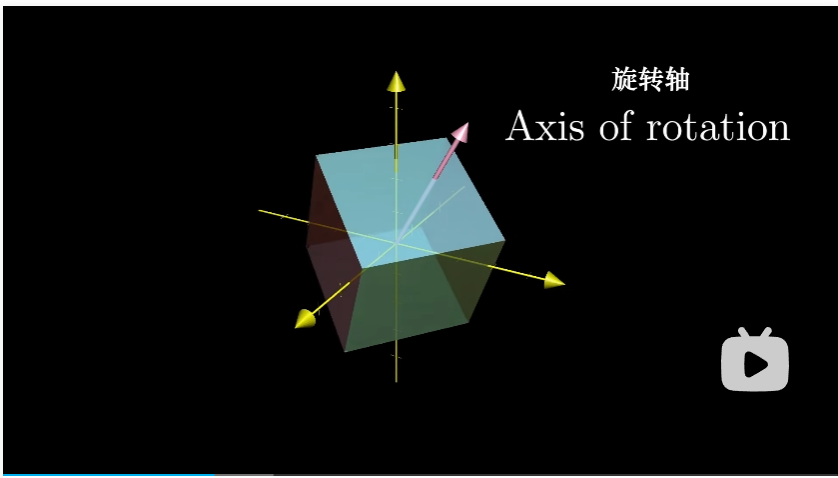
把一个三维旋转看成绕某个轴旋转一定角度,要比考虑相应的 $3 \times 3$ 矩阵要直观的多。

顺带提一下,这种旋转变换的特征值必须为 1,因为旋转并不缩放任何一个向量。
虽然我们可以通过看矩阵的列作为变换后的基向量来理解线性变换,但是理解线性变换作用的关键往往较少依赖于你的特定坐标系。更好的方法,则是求出它的特征向量和特征值。
这里概述一下计算特征值和特征向量的思想。首先我们用符号表示一下
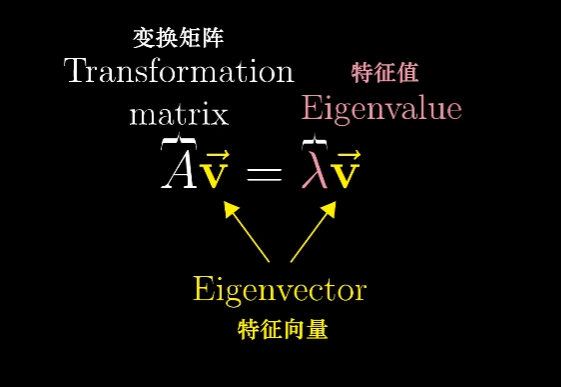
这个等式就是说,矩阵向量的乘积,等于特征向量 $v$ 乘以某个数 $\lambda$。为了使得两边的运算类型相同,方便计算,我们将等号右侧重写为某个矩阵向量的乘积

通常我们会提出因子 $\lambda$,写做 $\lambda \times I$,这样两边形式就统一了,我们进行移项,提出因子 $v$。那么问题就变为:寻找一个向量 $v$,使得这个新矩阵与 $v$ 相乘结果为零向量。

如果 $v$ 本身是零向量,那没什么意思。考虑 $v$ 为非零向量时,根据第五节和第六节的内容,我们知道,当且仅当矩阵代表的变换将空间压缩到更低维度时,才会存在一个非零向量,使得矩阵和它的乘积为零向量。而空间压缩对应的就是矩阵的行列式为 $0$,将行列式展开得到的含 $\lambda$ 的多项式,我们称之为特征多项式。
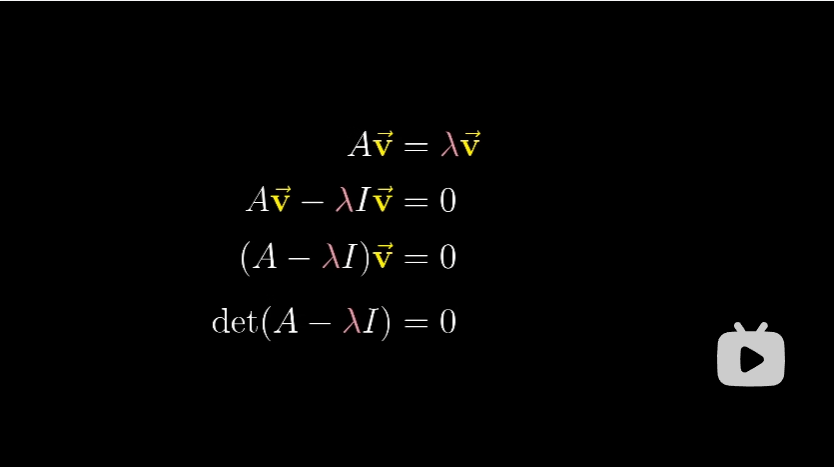
当我们找到特征多项式的一个解后,再将其带入矩阵 $A-\lambda I$ 中,然后求解出在经过这个对角线变换的矩阵变换后为零的向量,即为该特征值对应的特征向量。
不过二维线性变换不一定有特征向量(不考虑复数域的话),例如一个逆时针旋转90°的变换,它并没有特征向量,因为每一个向量都发生了旋转并离开了其张成的空间。
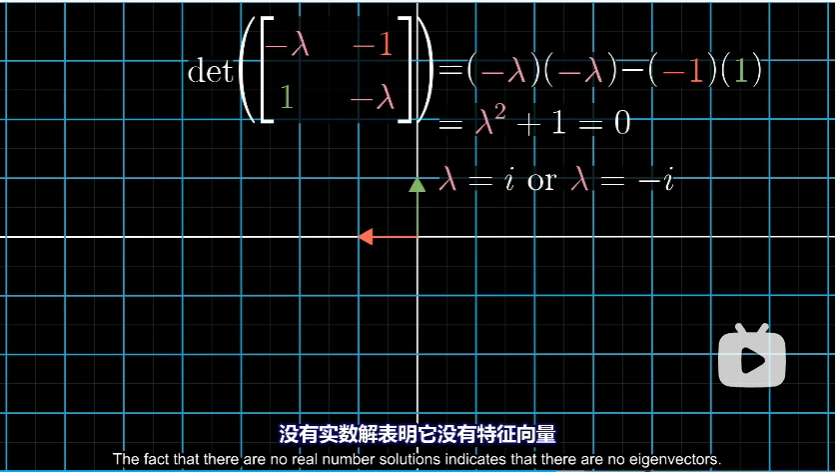
另一种剪切变换,

$x$ 轴上的向量就是所有的特征向量。
另外,可能会出现只有一个特征值,但是特征向量不止在一条直线上的情况。
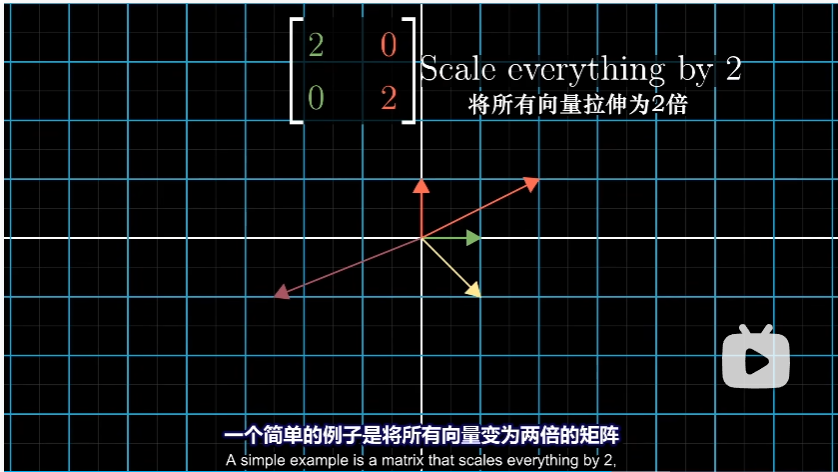
上述例子唯一的特征值是 2,但是平面内每一个向量都是属于这个特征值的特征向量。
最后我们介绍一下特征基,这很大程度依赖上一节的内容。
如果我们的基向量恰好是特征向量会发生什么? 比如将 $\hat i$ 变为原来的 $-1$ 倍,$\hat j$ 变为原来的 2 倍。那么相应的矩阵就是变换后 $\hat i,\hat j$ 的列向量。
注意到位于矩阵对角线上的值是 $\hat i,\hat j$ 变换的倍数,正好也是它们所属的特征值。而其余位置的元素为 0。这种除了对角线以外其他元素均为 0 的矩阵被称为对角矩阵。
解读它的方法是,所有基向量都是特征向量,矩阵的对角元(对角线上的元素)是它们所属的特征值。
对角矩阵在很多方面都更容易处理,其中一个重要的方面是,矩阵与自己多次相乘的结果更容易计算。因为对角矩阵仅仅让基向量与某个特征值相乘,所以多次应用矩阵乘法,比如 100 次,也只是将每个基向量与对应特征值的 100 次幂相乘
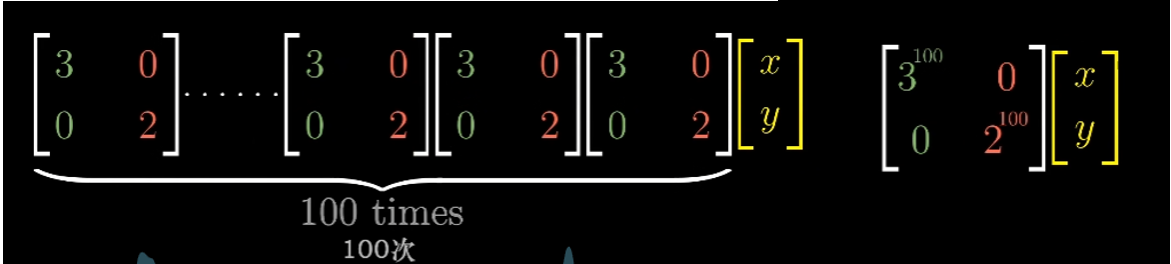
相比之下,尝试计算一个非对角矩阵的 100 次幂简直就是一场噩梦(对于笔算来说)。
当然,对于基向量同时也是特征向量的情况是非常少的。但是如果我们的变换有许多特征向量,(能张成全空间,比如二维变换矩阵有两个不共线的特征向量)
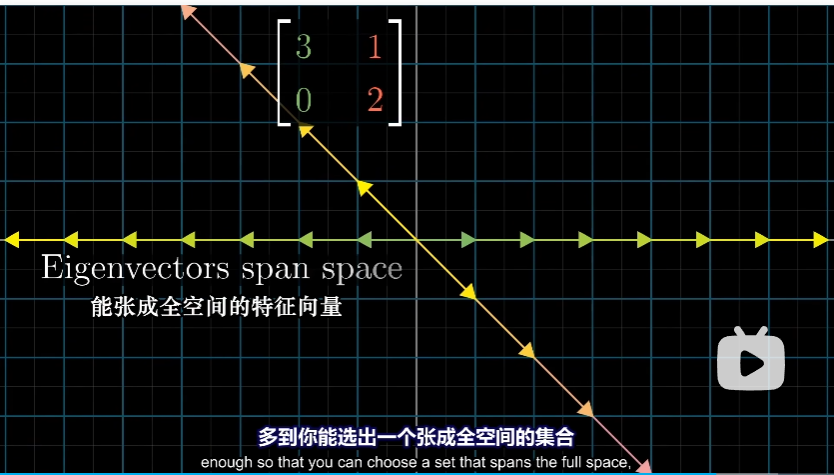
那么我们就可以变换坐标系,使得这些向量为特征向量。
以上图的变换为例,首先我们取出想用做新基的向量坐标,即两个特征向量,并将它们作为一个矩阵的列。这个矩阵就是基变换矩阵。
然后在右侧写下基变换矩阵,左侧写下基变换矩阵的逆矩阵。当原始的变换矩阵夹在这两个矩阵中间时,所得到的复合矩阵代表的其实是同一个变换,只不过是从新基向量所构成的坐标系的角度来看的。
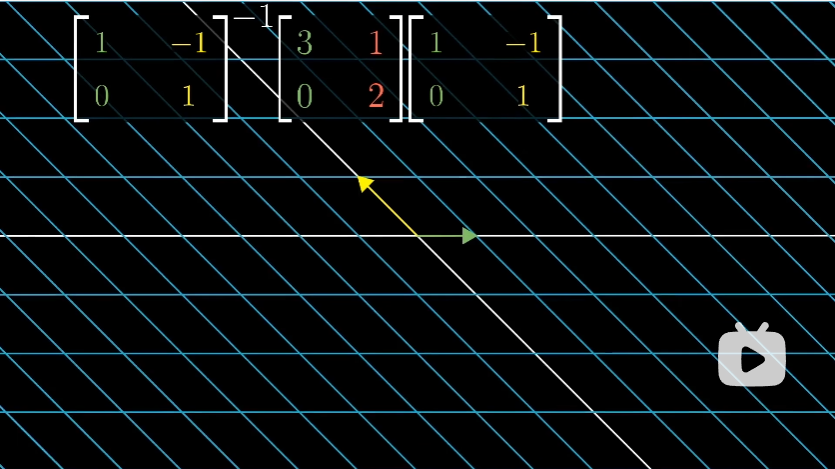
用特征向量来完成这件事的意义在于,这个新的矩阵必然是对角的,并且对角元为对应的特征值。这是因为它所处坐标系的基向量在变换中只进行了缩放。这种转化也被称为对角化。
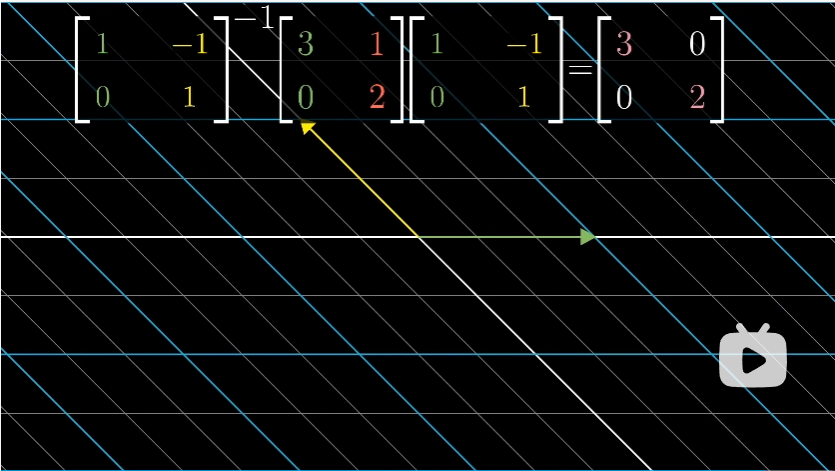
一组由特征向量组成的基向量被称为 ”特征基“ 还是很自然的叭。
所以在计算某个矩阵的 100 次幂,一种更容易的做法就是先变换到特征基,在那个坐标系中计算 100 次幂,然后在转回来。
不过并非所有的变换都能进行对角化,比如剪切变换,特征向量不够多,不足以张成全空间;二维平面的旋转变化就更不用说了,都没有特征向量。

sagemath
1 | sage: a = matrix([[3,1],[0,2]]) |
10.1 计算二阶矩阵特征值的妙计
(这部分内容对于那些还需要考试的同学应该比较有用)
常规计算特征值的方法都是:将对角线上各项减去 $\lambda$,然后去求行列式为 0 时的根。这过程需要花好几步来展开、化简来得到一条二次多项式,也就是矩阵的特征多项式(Characteristic polynomial)。这条多项式的根就是特征值。如果求根还要用一下二次求根公式,则还要再花一两步来化简
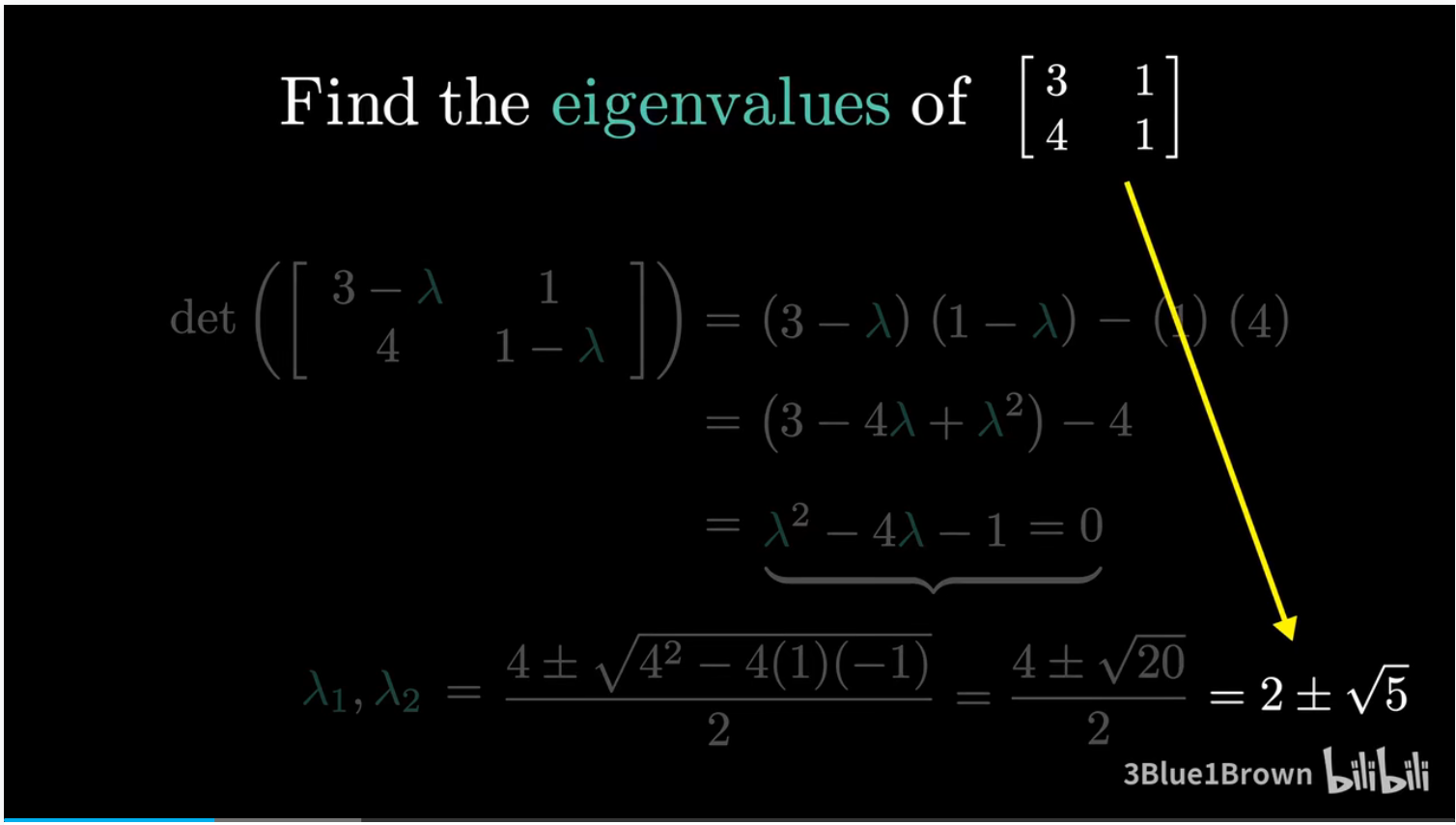
不过对于二阶矩阵,这里有一种更直接的方法来算出结果,其中涉及三个知识点。
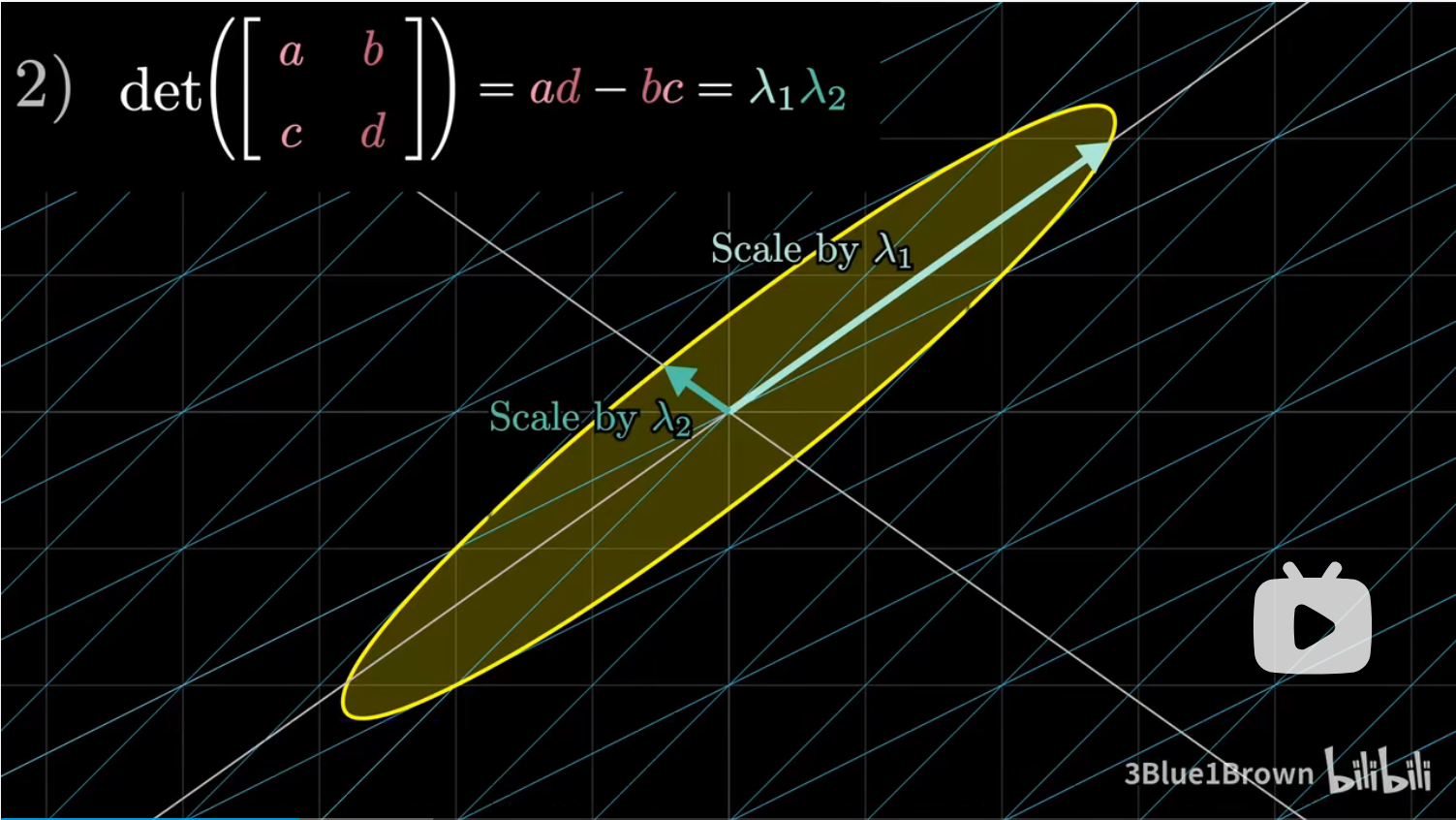
矩阵的迹(trace)(也就是主对角元的总和)和特征值得总和相等。不过换种讲法对我们更有用,即两特征值的平均数等于两个主对角元的平均数,我们记为 $m$。
(二阶)矩阵的行列式计算(就是我们常见的公式:$ad-bc$ )等于两特征值的乘积。我们记为 $p$

这一点不难理解,特征值描述了变换在特定方向上将空间进行拉伸的程度,而行列式则描述了变换将面积或体积整体进行拉伸的程度。
接下来考虑如何推出第三点:
以 $m=7,p=40$ 距离,我们知道两个特征值在数轴上的位置以 7 为中心对称,即二者的数可以写作 $7 \pm d$ ,我们还知道他们的乘积是 $40$,因此我们可以用一个平方差公式就能得到 $d$ 了。
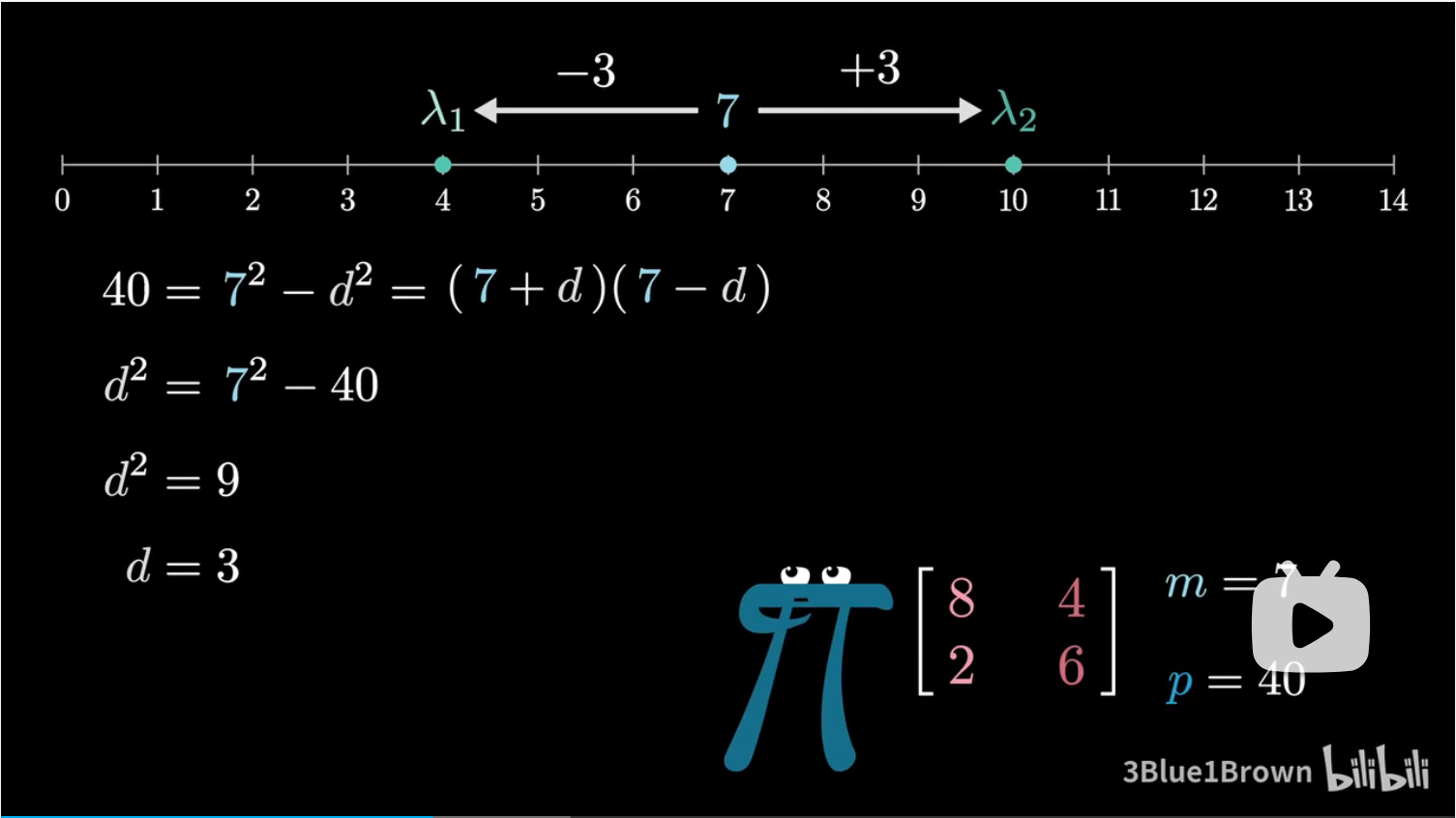
于是两个特征值就是 $4,10$。
我们将上述过程浓缩成一个通用的公式,对于任意均值 $m$ 和乘积 $p$,均值到根的距离的平方为 $m^2-p$,因此特征值分别等于 $m \pm \sqrt{m^2-p}$

相比于传统的求根公式,这个方法需要记忆的符号变少了(虽然二次求根公式可能已经快刻进中国学生的 DNA 里了),并且我们可以直接从矩阵元素中读出特征值的均值 $m$ 和乘积 $p$,不需要再走一遍流程先去得到特征多项式再求解。

11 抽象向量空间

接下来将重新探讨一下该系列第一节中一个看似简单的问题:向量是什么?
比如一个二维向量,它是平面内的一个箭头?而为了方便起见,我们用坐标来描述它。或者说它是一个实数对?而我们只是将他形象的理解为平面内的一个箭头。亦或者,这两种观点只是更深层次的东西的体现?
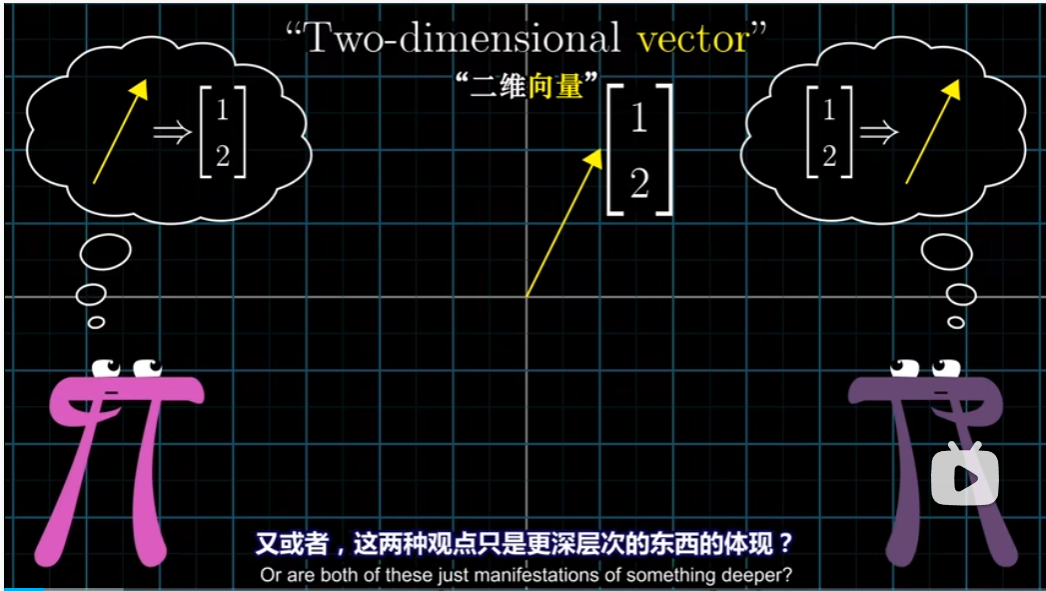
一方面,将向量解释为一种数字给人感觉清晰明了,四维向量或者一百维向量看上去就像是可以操作的真实具体的概念。与之相反,四维空间之类的东西就只是一个模糊的几何概念。
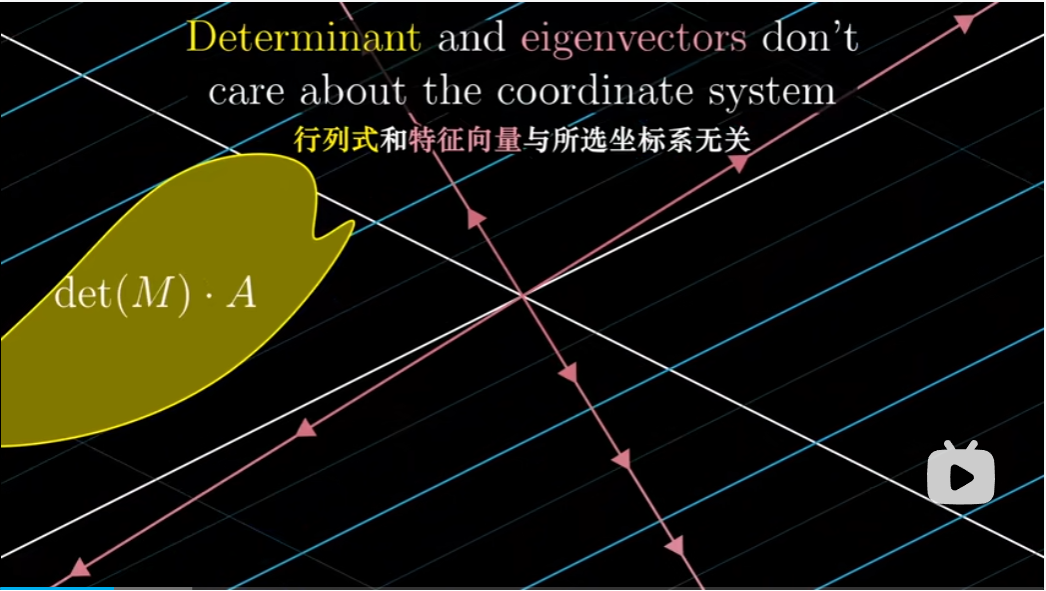
但是另一方面,对于那些在实践中运用线性代数的人,尤其是熟悉基变换的人来说,他们通常感觉所处理的空间独立于坐标存在。而且坐标描述实际上有一些随意,因为坐标系依赖于我们所选择的基向量。而线性代数的核心话题,如行列式、特征向量等,他们似乎不受所选坐标系影响。行列式告诉我们的是一个变换对面积的缩放比例,特征向量则是在变换中留在它所张成空间中的向量。这二者都是暗含于空间中的性质,我们可以自由选取坐标系而不改变它们最根本的值。
但是,如果向量根本并不是由一组实数构成的,它们的本质更具有空间性,这不禁让人产生疑问:那么数学家所说的”空间“或”空间性“是什么意思?为了进一步说明,我们将探讨一些既不是箭头,也不是一组数据,但是同样具有向量特性的东西。比如函数。
从某种意义上说,函数实际上只是另一种向量,类比两个向量相加,我们也可以将两个函数 $f,g$ 相加,从而得到一个新的函数 $(f+g)$。新的函数在任意一点处的值,就是 $f$ 和 $g$ 在这一点处的值的和,即 $(f+g)(x) = f(x) + g(x) $。这个向量对应坐标相加非常相似,只不过函数由无穷多个坐标要想加。类似的,函数与一个实数相乘也有合理的解释,就是把输出的值与那个数相乘。这再次和向量对应坐标数乘类似,只是函数有无数多个坐标要乘。
对函数的线性变换也有一个合理的解释,这个变换接受一个函数,并把它变换为另一个函数。从微积分中我们可以找到一个常见的例子——导数。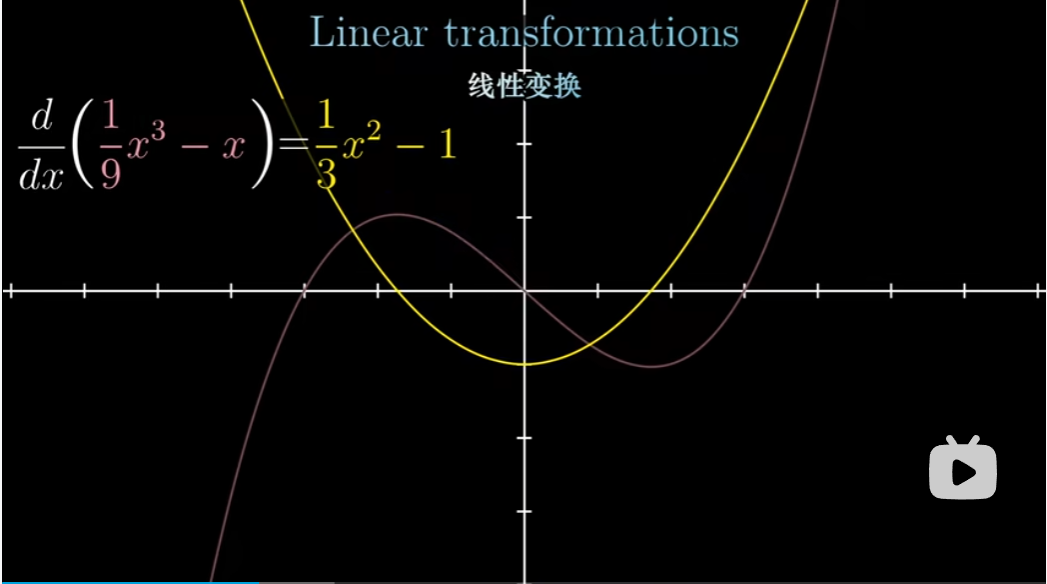
不过有时候它叫另外的名字:线性算子。
我们自然想问,”一个函数的变换是线性的“ 是什么意思。满足以下两条性质的变换是线性的:可加性、成比例。
可加性意味着如果你把两个向量 $v,w$ 相加,然后对它们应用变换,得到的结果和将变换后的 $v$ 和变换后的 $w$ 相加一致

成比例是说,你将一个向量 $v$ 与某个数相乘,然后应用变换,结果等价于变换后的 $v$ 与这个数相乘

这就是我们经常听到的一种描述方法:”线性变换保持向量加法运算和数乘运算“
在微积分中,求导是具有可加性和成比例性的
先加再求导,等于先求导再加。

先数乘再求导,等于先求导再数乘

为了掌握这里的类比关系,我们可以用矩阵来描述求导的样子。
现在我们把注意力放在多项式空间上,虽然这个空间中的每个多项式都只有有限项,但是整个空间应该包含任意高次的多项式

首先我们需要给这个空间赋予坐标的含义,这需要选取一个基。因为多项式已经是数乘 $x$ 的不同幂次再求和的形式,于是很自然的我们取 $x$ 的不同幂次作为基。换句话说,第一个基函数就是一个常函数,即 $b_0(x) = 1$,第二个基函数是 $b_1(x) = x$,然后是 $b_2(x) = x^2 ,b_3(x) = x^3\cdots$ 以此类推

基函数在这里其的作用就和前面 $\hat i,\hat j,\hat k$ 在箭头世界中起到的作用类似。
因为多项式的次数可以任意高,所以这个基函数集也是无穷大,这也就意味着我们的向量会有无穷多个坐标。



在这个坐标系中,求导是用一个无限阶矩阵来描述的,其中绝大部分是零,不过次对角线上按序排列着正整数。


求导满足线性性质,使得上述这种求导方式成为可能。
而构建这个求导矩阵的方法就是:求每一个基函数的导数,然后把结果放在对应列。
乍一看,矩阵向量乘法和求导毫不相干,但他们其实是一家人,都是线性变换。实际上,这个系列中我们所讨论过的大部分关于向量(空间中的箭头)的概念,在函数世界都有直接的类比。

那么回到”向量是什么”这个问题上,其实这里想指出的是,数学中有很多类似向量的事物,只要我们处理的对象集合具有合理的数乘和相加概念,不管是箭头,数对,还是函数,线性代数中所有关于向量、线性变换和其他的概念(点积、零空间、特征向量)都应该适用于它。
在线性代数中,如果要让所有已经建立好的理论和概念适用于一个向量空间,那么它必须满足八条公理

我们在决定对一个概念应用线性代数的结论之前,只要验证其定义是否满足这些需求即可。

因此,我们往往会把所有结论都抽象地表述出来,也就是说仅仅根据这些公理表述,而不是集中于某一种特定的向量,像是空间中的箭头或者函数等。
所以对于“向量是什么”这个问题,数学家会直接忽略不答。向量的形式并不重要,箭头、一组数、函数、$\pi$ 生物等都无所谓,只要向量相加和数乘的概念遵守以上公理即可。(线性代数也抽象起来了呢。。。)

12 克莱姆法则,几何解释
 )
)
下面是一个大家会在线性代数课本上见到的使用克莱姆法则求方程组解的例子
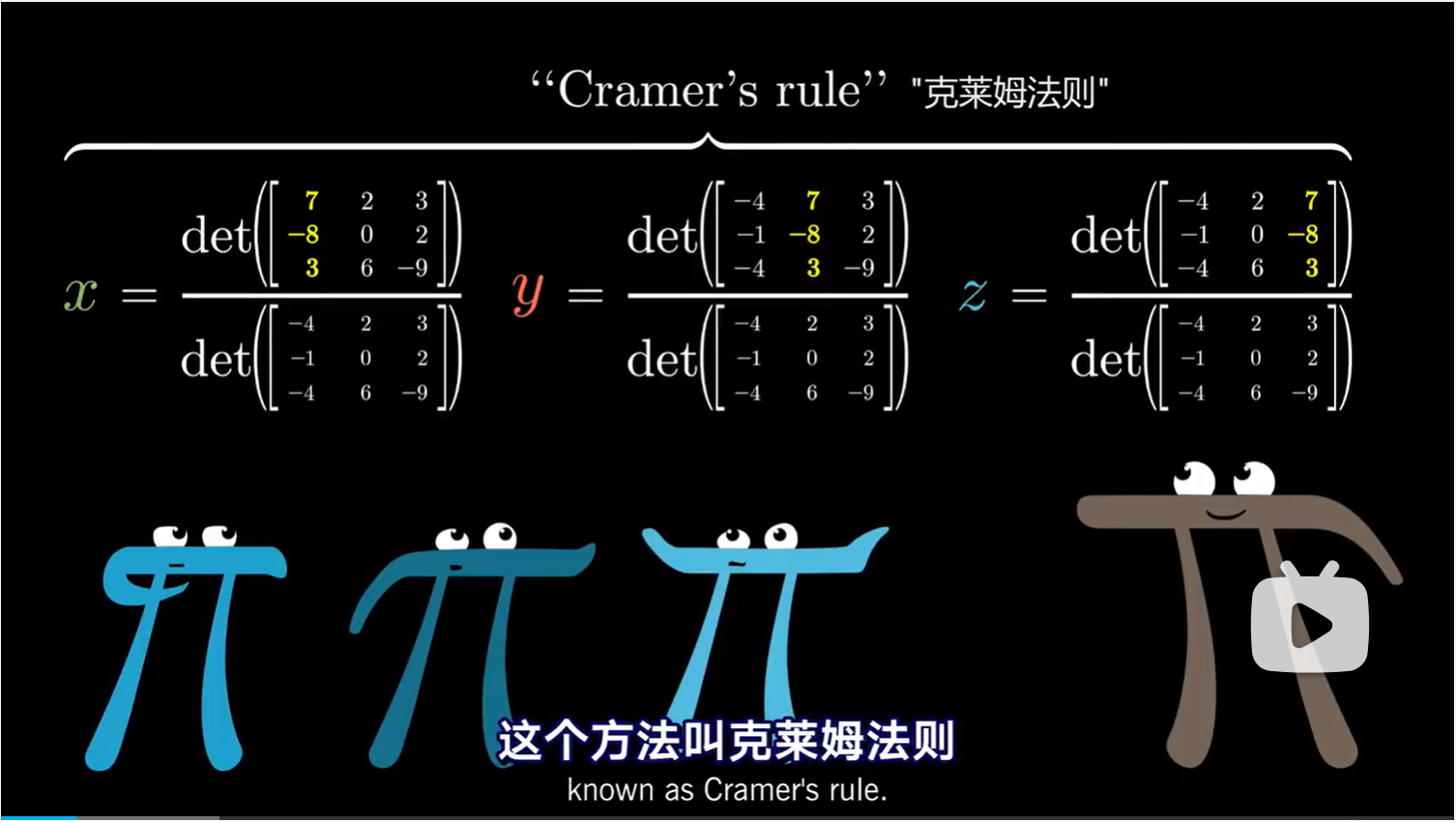
虽然但是,克莱姆法则并不是计算线性方程组最好的方法,比如高斯消元法,会算的更快。所以这里学习克莱姆法则不妨是当作拓展视野,帮助我们加深对线性方程组的理解。并且从纯美学角度来说,它的最终结果很值得欣赏和思考。
我们先从线性方程组讲起,(原则上,只要未知数与方程的个数一样,我们讲的都适用,所以不妨用一个小的例子)像之前一节内容所说,我们可以把方程组看作是对一个 $[x \ y]$ 向量进行一个已知矩阵的变换,而且变换后的结果已知。 所以问题就变成了哪个输入向量 $[x \ y]$ 在变换后会成为已知输出向量。
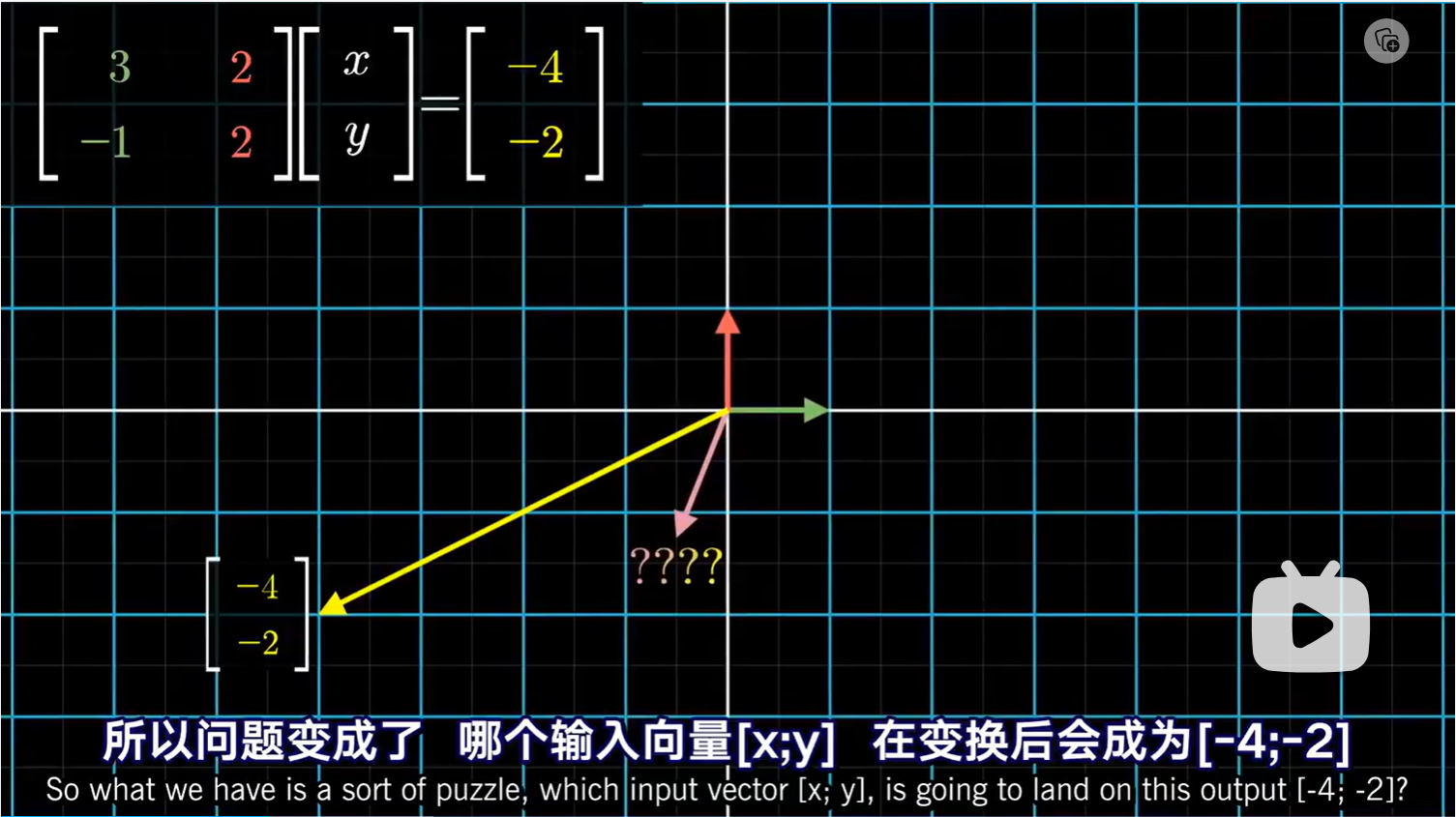
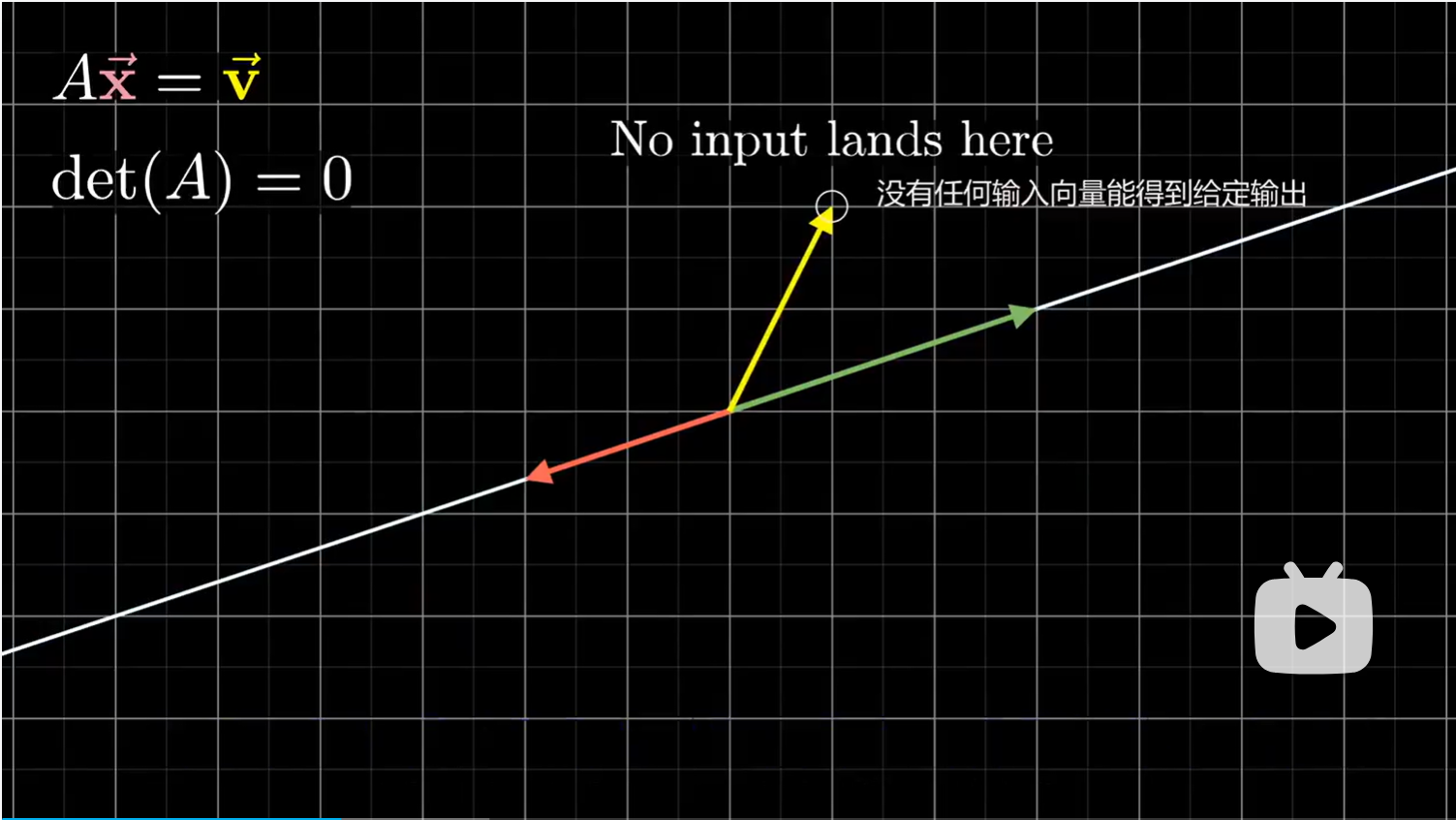
一种思路是,我们已知的向量可以看作是矩阵列向量的一个线性组合:$x\hat i+y\hat j$。但我们希望能准确地计算出 $x,y$ 的值。注意,这里的结果取决于矩阵变换是否降维。如果行列式为 0 ,在这种情况下,要么任何输入向量都不会变换到给定得输出向量,即 0 解。
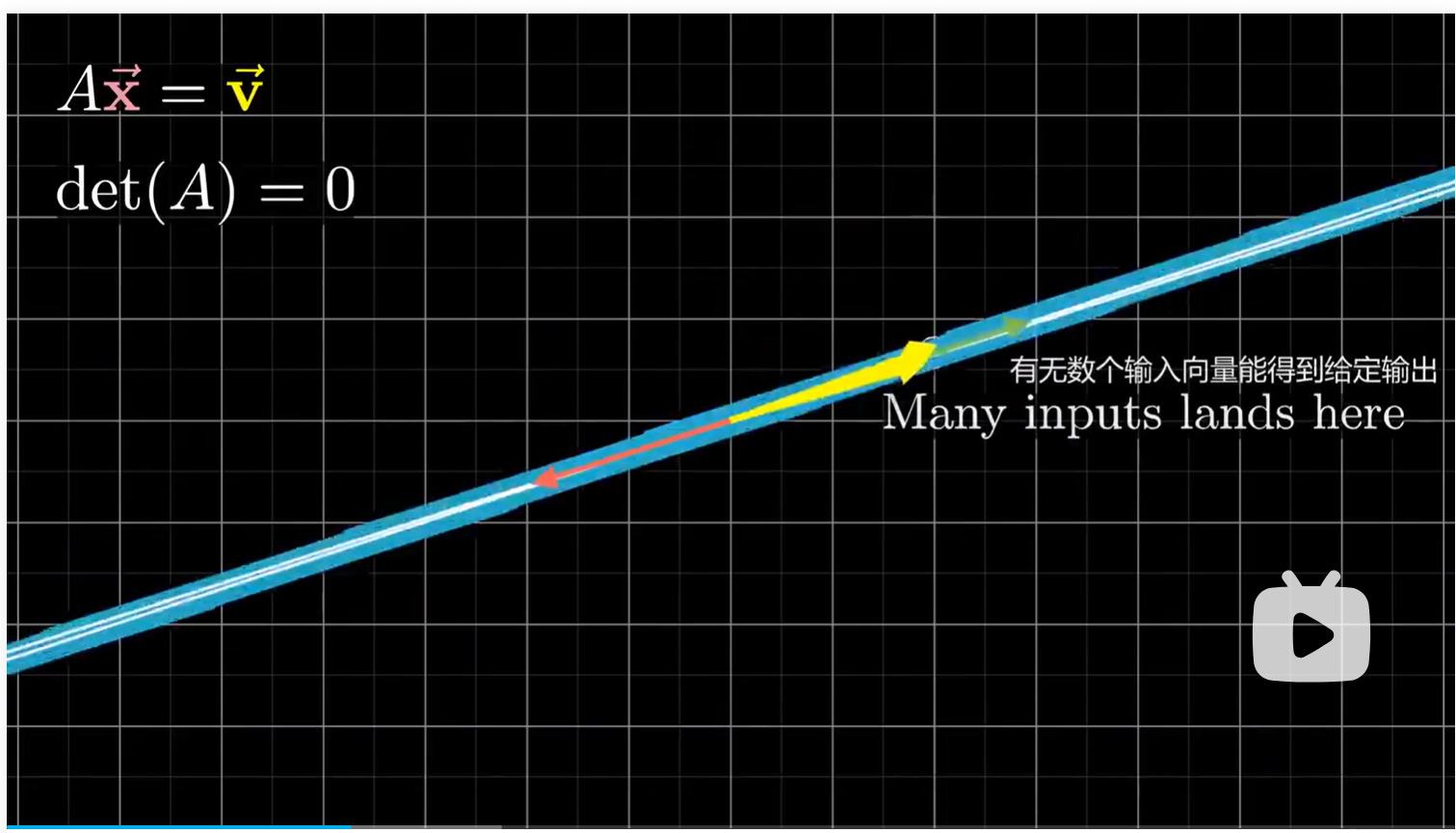
要么有无数个向量都会变换到给定的向量,即无数解。
不过这里我们只讨论非零行列式的情况,即每个输入向量有且仅有一个输出向量,且每一个输出向量也仅对应一个输入向量。
接下来是一个错误的例子,但是它的大方向是对的,能够帮我们引出后续的结论。
首先,我们知道未知向量 $[x \ y]$ 的 $x$ 坐标是它与第一个基向量 $[1 \ 0 ]$ 的点积;同样,它的 $y$ 坐标是与第二个基向量 $[0 \ 1]$ 的点积。
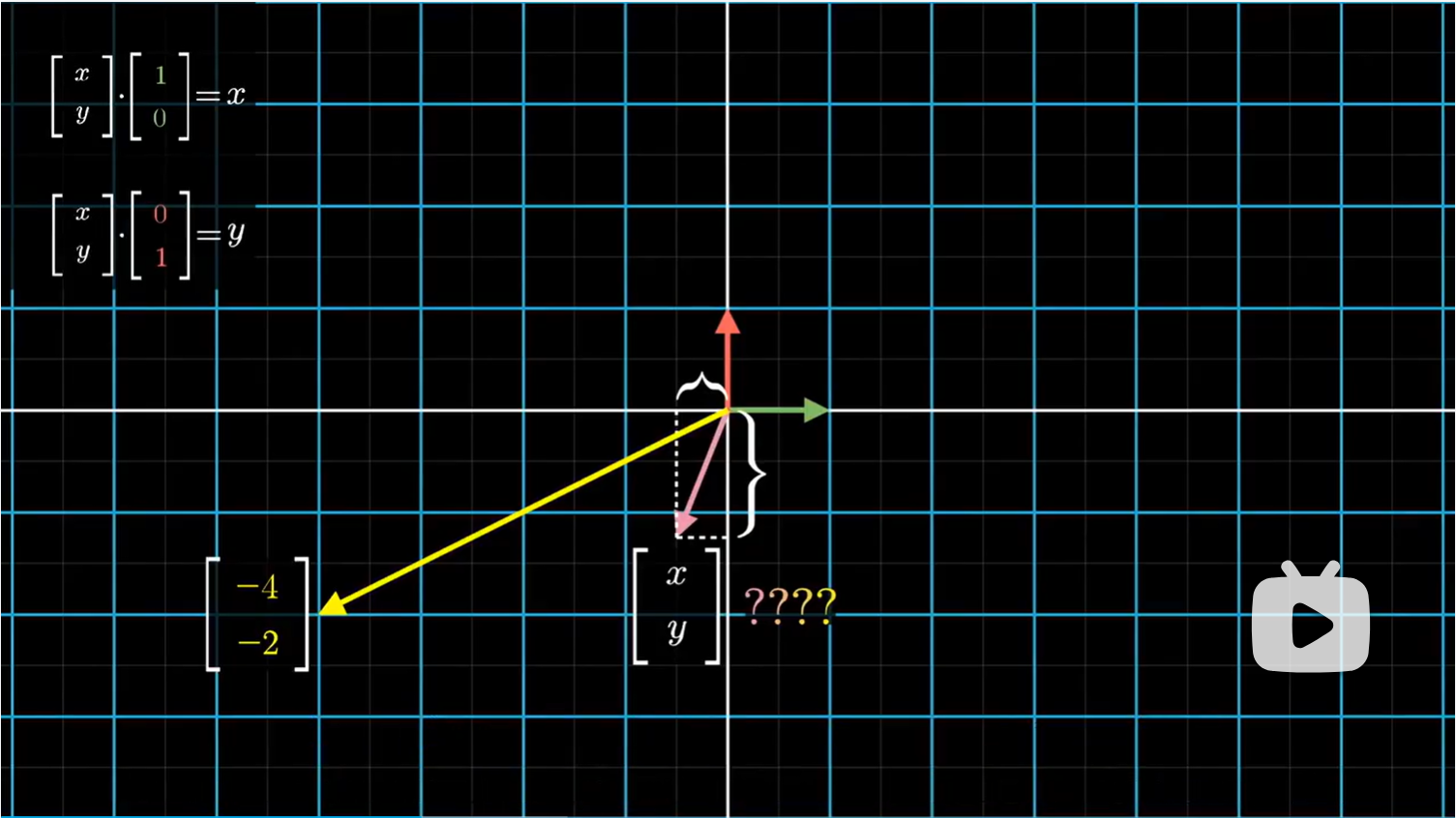
所以也许,我们希望在矩阵变换后,变换后的未知向量与变换后的两个基向量的点积也等于原来的 $x,y$ 坐标,这样就非常好了,因为 3 个变换后的向量都是已知的。
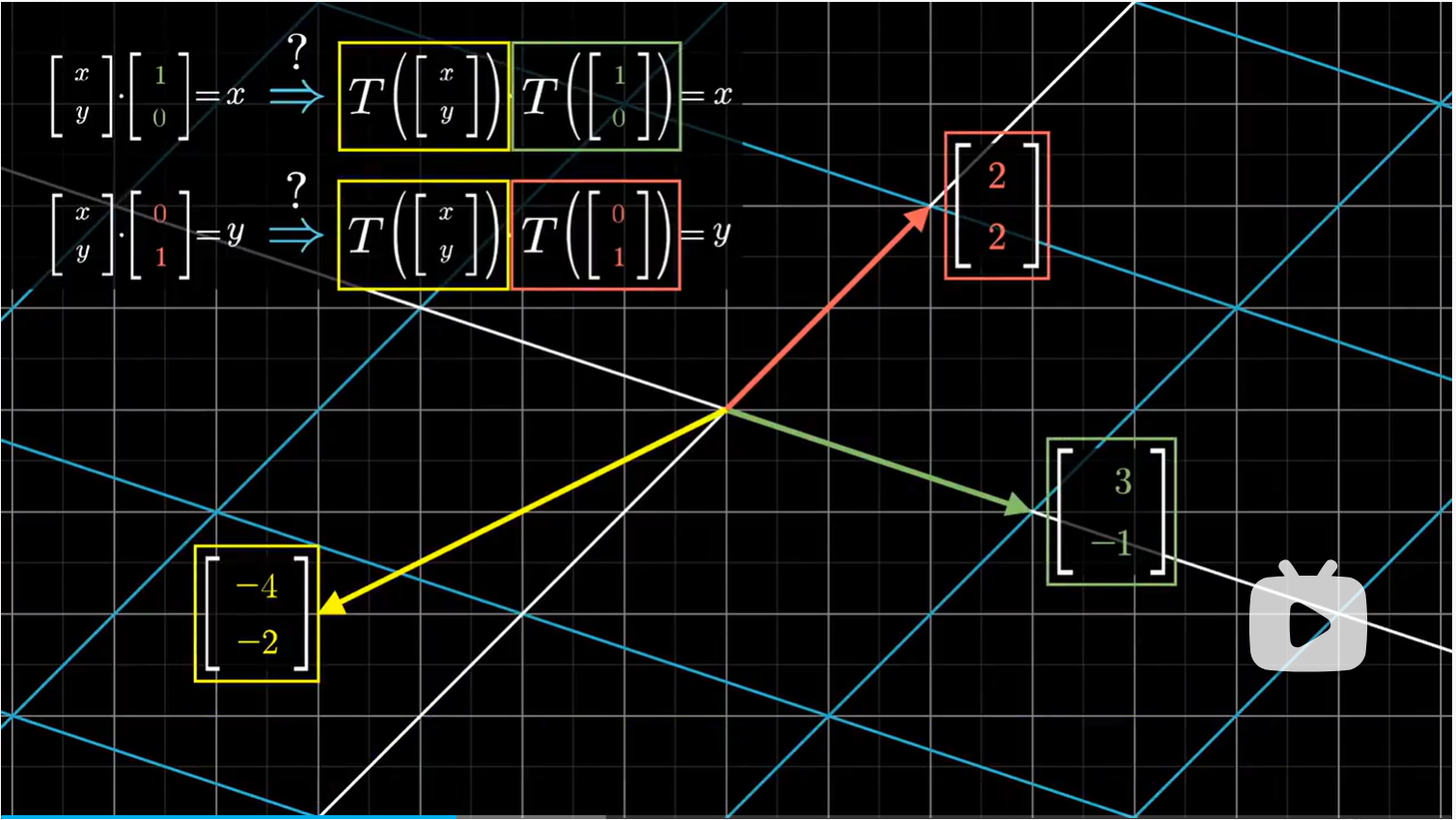
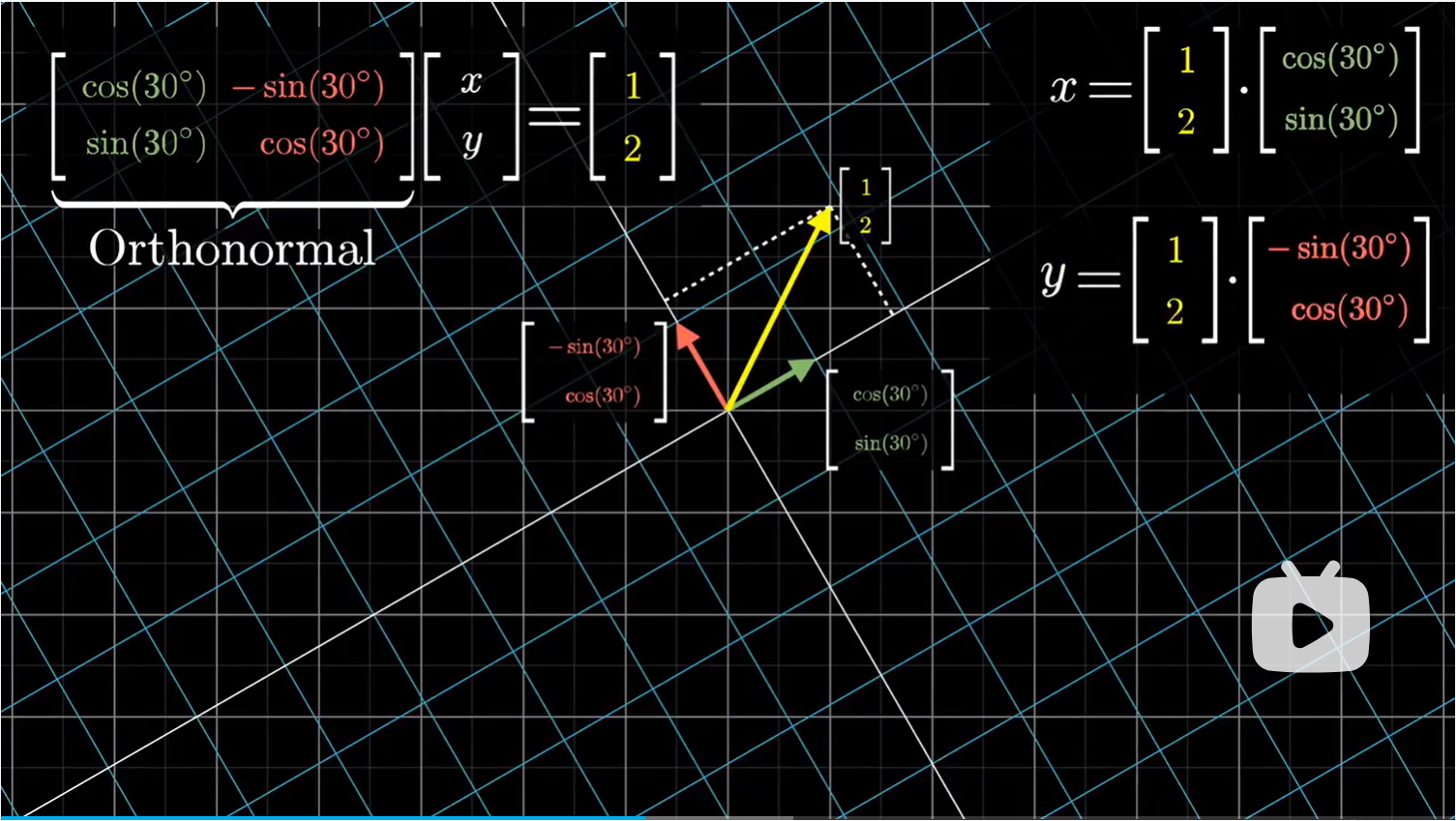
不过很可惜,这样的假设是不成立的。对于大多数线性变换来说,点积会随着变换而改变。事实上,那些不改变点击的矩阵变换,就是正交变换。例如旋转矩阵。

用正交矩阵来求解线性系统是非常简单的,因为点积保持不变,此时上述我们的猜想成立,已知的输出向量和矩阵的列向量的点积,分别等于未知输入向量和各个基向量($\hat i,\hat j$)的点积,也就是输入向量的每一个坐标。
虽然这个思路对大多数线性方程组都不成立,但是给了我们一个思考的方向。有没有另一种对输入向量坐标值的几何解释能在矩阵变换后保持不变呢?
考虑第一个基向量 $\hat i$ 和未知输入向量 $[x \ y]$ 组成的平行四边形,面积是长度为 $1$ ($|\hat i| = 1$) 的底乘以与底边垂直的高,也就是 $y$。
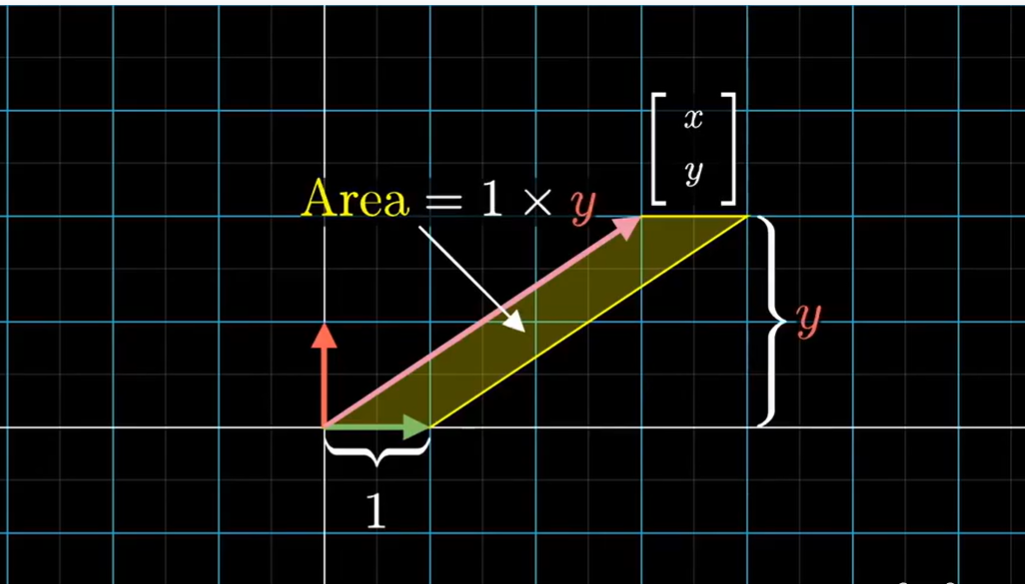
因此我们拐着弯的用一个平行四边形来表示了 $y$ 值。不过更准确的来说,我们应该考虑这个平行四边形的有向面积,如果向量 $y$ 坐标为负,则四边形面积也为负。(前提是把基向量 $\hat i $ 放在第一位来定义这个平行四边形)
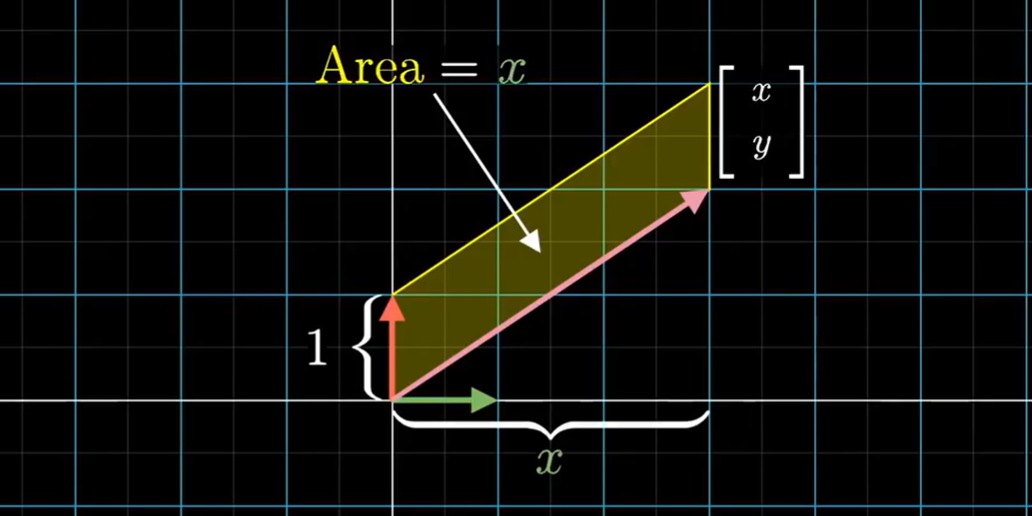
用同样的方法来观察未知输入向量 $[x \ y]$ 和第二个基向量 $\hat j$ 组成的平行四边形,那么它的面积就等于向量 $x$ 的坐标。
举一反三考虑三维情况下的话,向量 $z$ 的坐标值就是未知输入向量和另外两个基向量 $\hat i ,\hat j$ 所组成的平行六面体的体积。
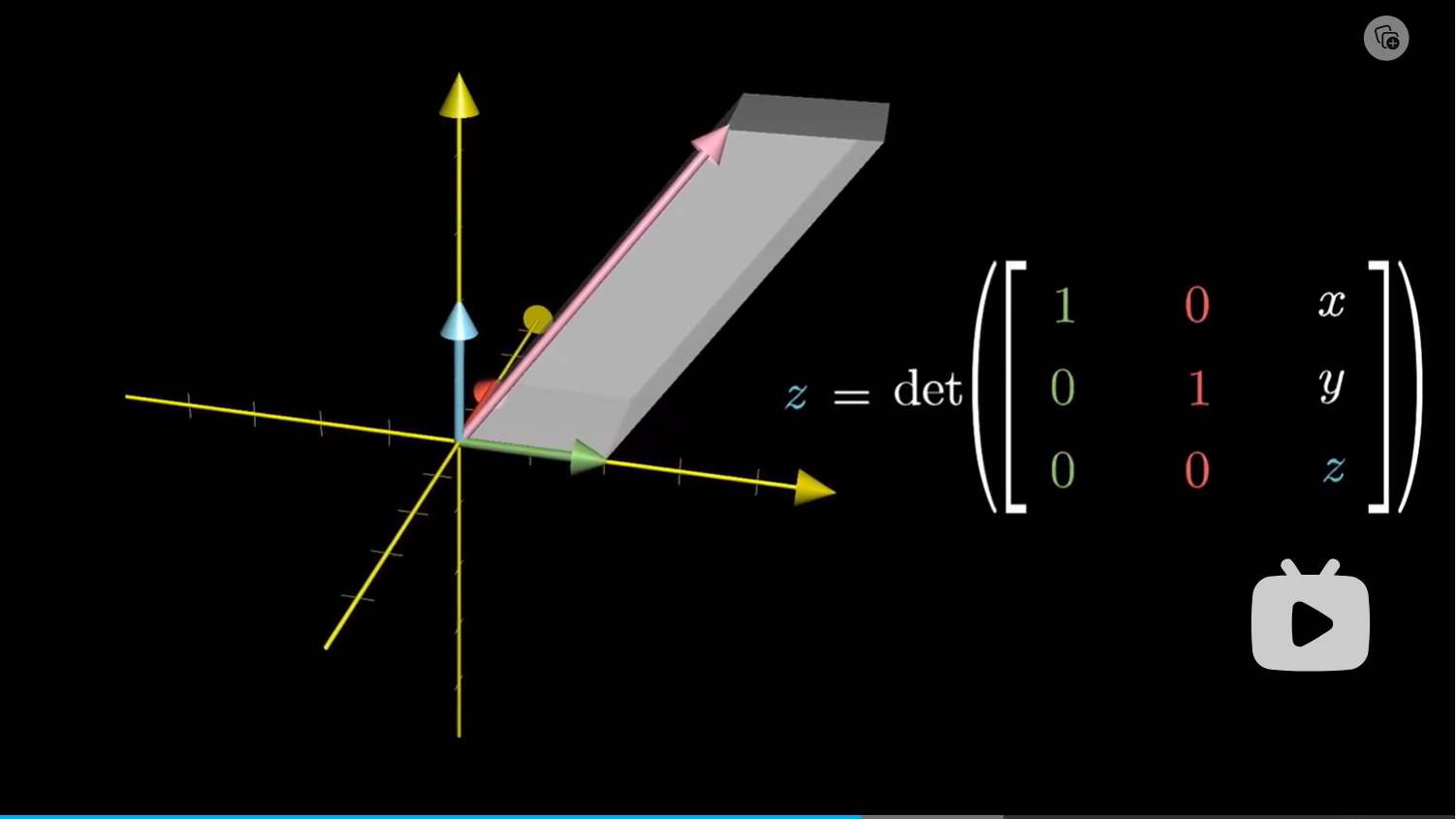
底面是由基向量组成的面积为 1 的正方形,所以它的体积值值就等同于它的高,也就是我们这个向量的 $z$ 坐标值。同样的,我们也可以用这个”奇怪的方法“来描述其他向量在某一个轴上的坐标值:考虑向量和除这个轴之外的另外两个基向量组成的平行六面体,然后体积就是对应的坐标值。
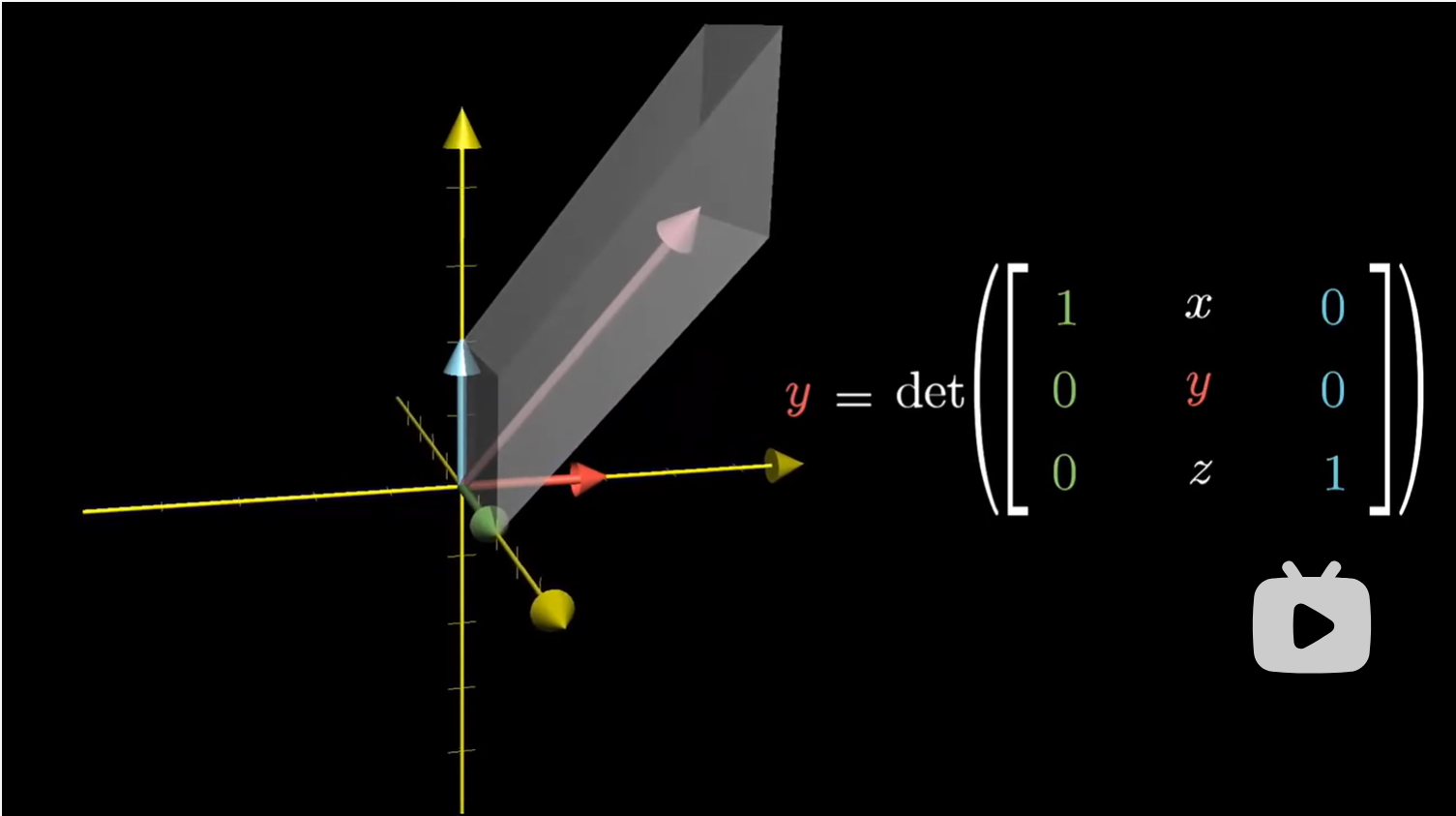
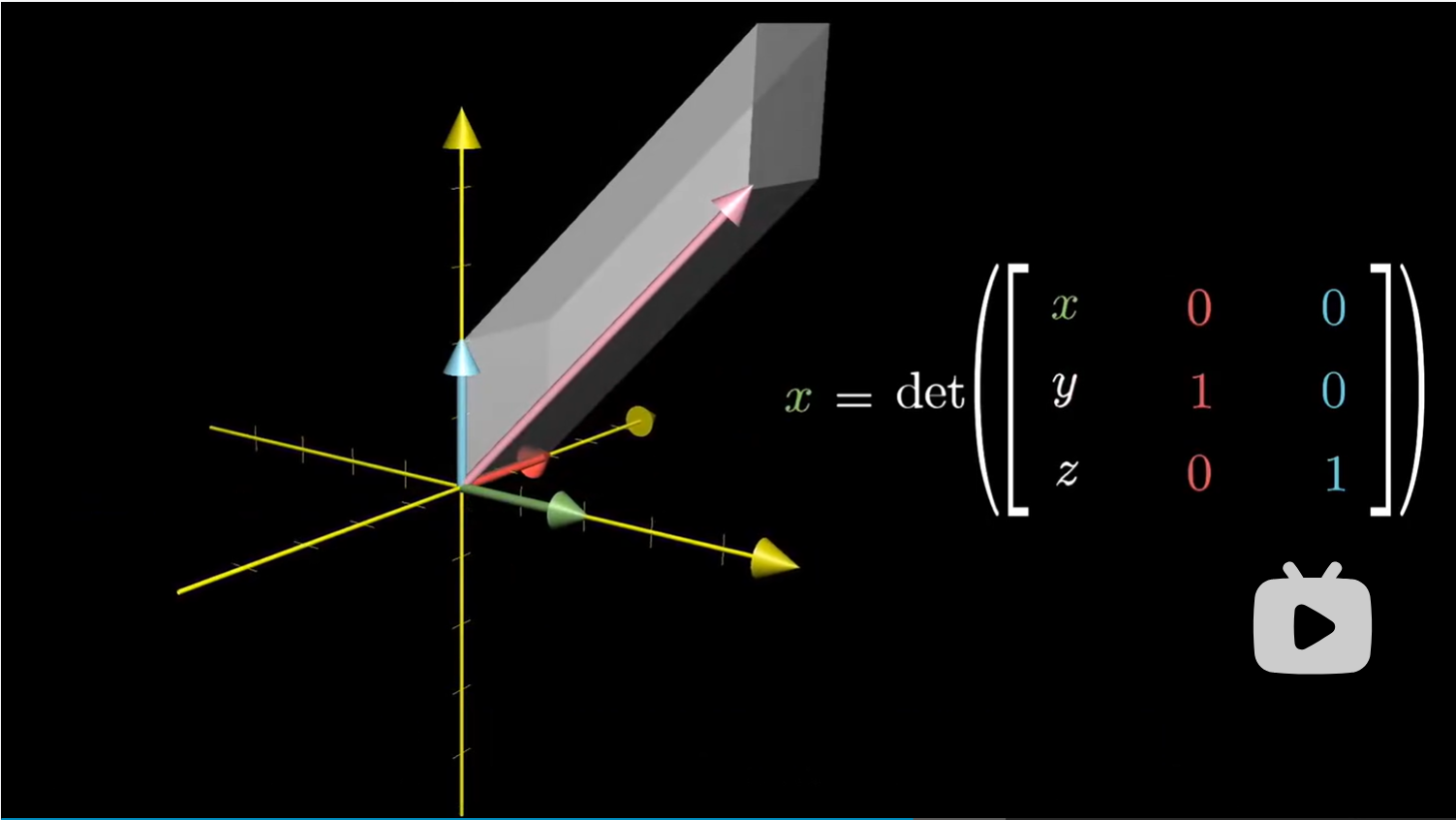
另外,考虑平行六面体的有向体积,就是之前在行列式一节中提到的右手法则。
那么为什么要把坐标和面积或者体积联系起来呢?因为当我们做了矩阵变换后,平行四边形的面积可能成比例的伸缩。但是请注意,所有面积伸缩的比例都等于给定的行列式。
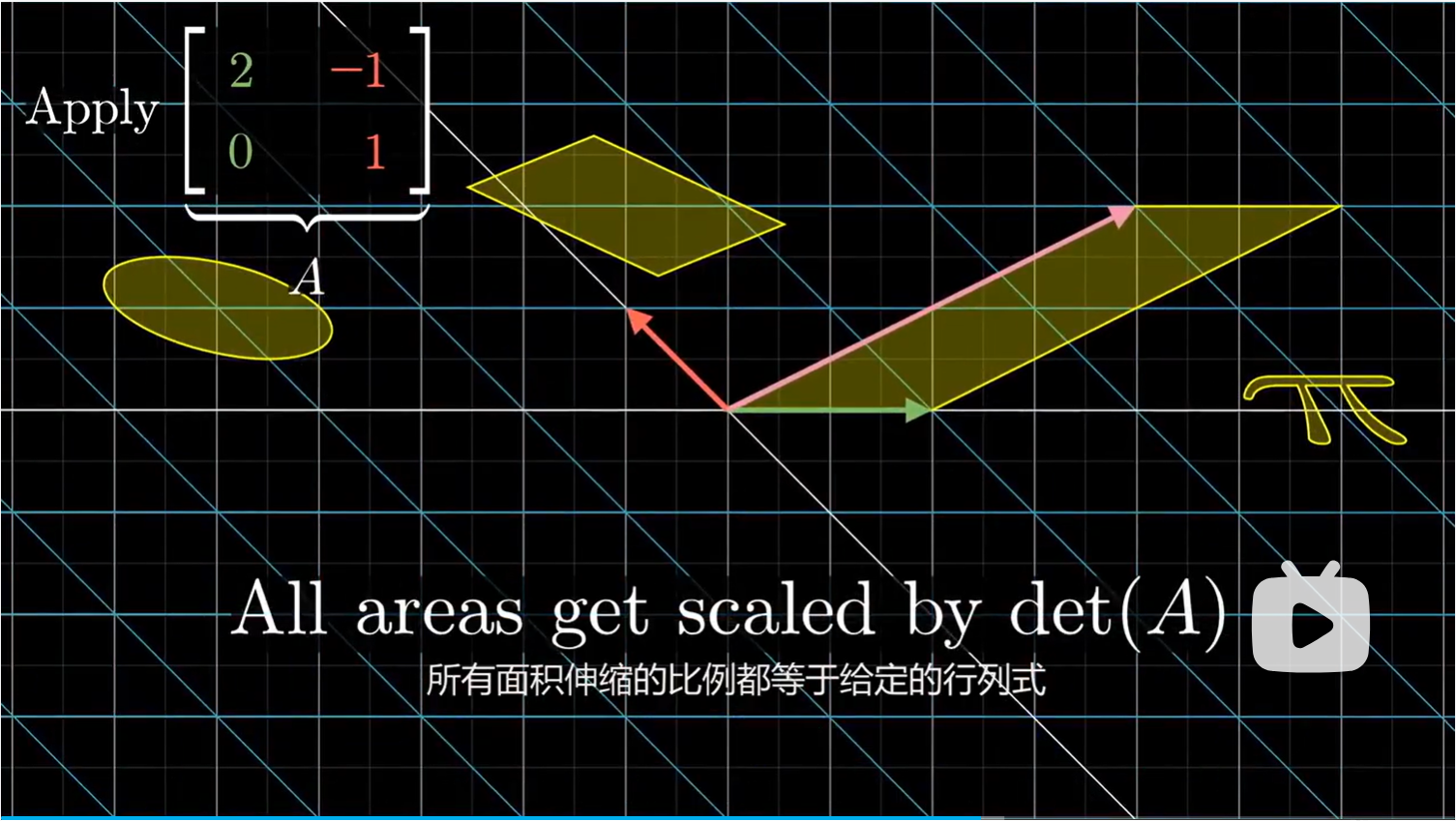
因此,变换前平行四边的面积等于 $y$ 值,那么变换后的面积就等于矩阵的行列式乘以 $y$ 值。因此,可以用输出的平行四边形的面积,除以矩阵的行列式计算出 $y$。至于平行四边形的面积的计算,因为我们已知最终变换后的向量,那么我们可以构造一个新的矩阵,第一列和原来相同(变换后的 $\hat i$),但是第二列是输出向量,然后取新矩阵的行列式。因此,我们只需要使用到变换后的向量:即矩阵的两个列向量和已知输出向量就能计算得出未知输入向量的 $y$ 值了。
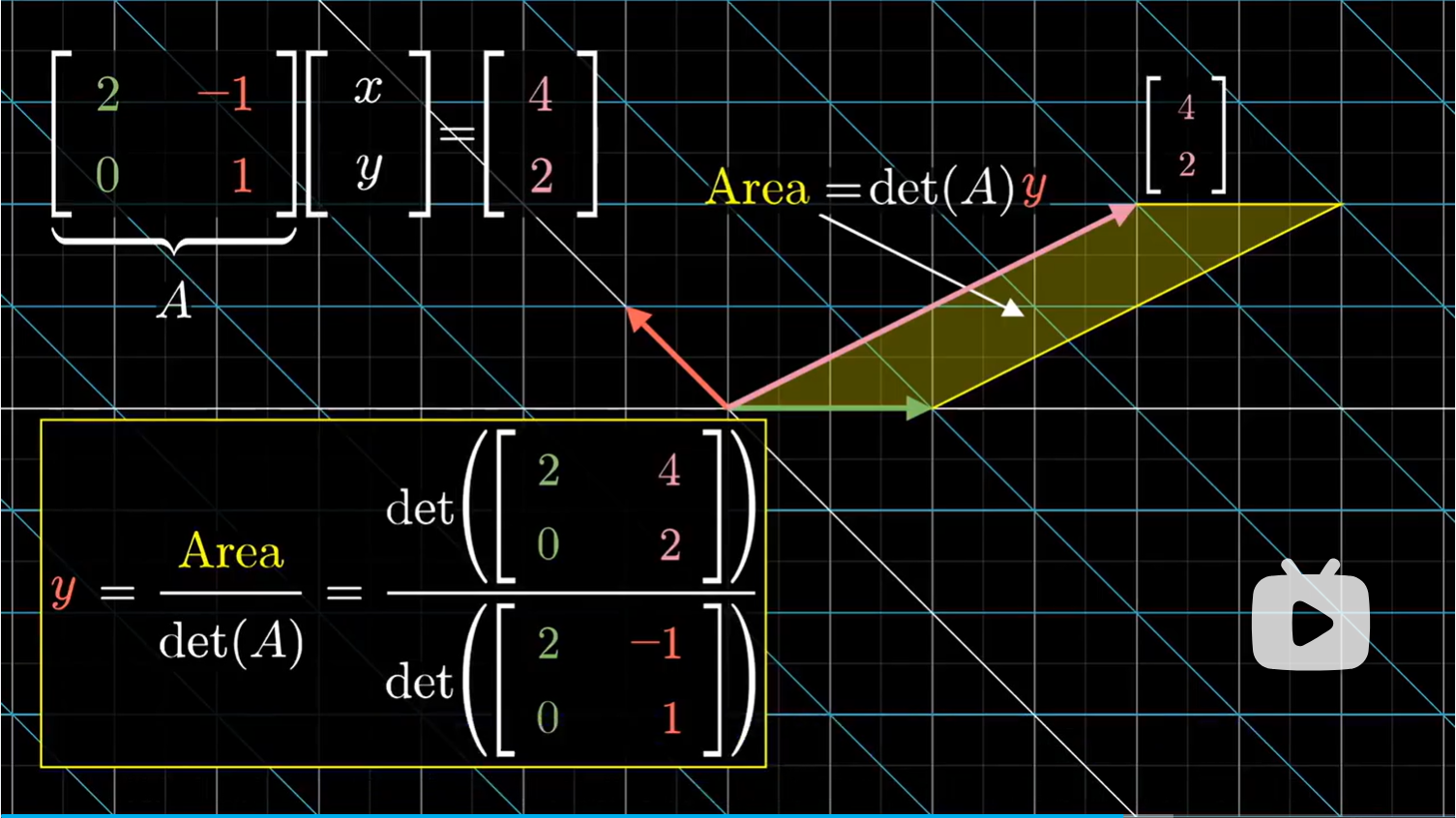
我们也可以用同样的方法得到 $x$ 值。
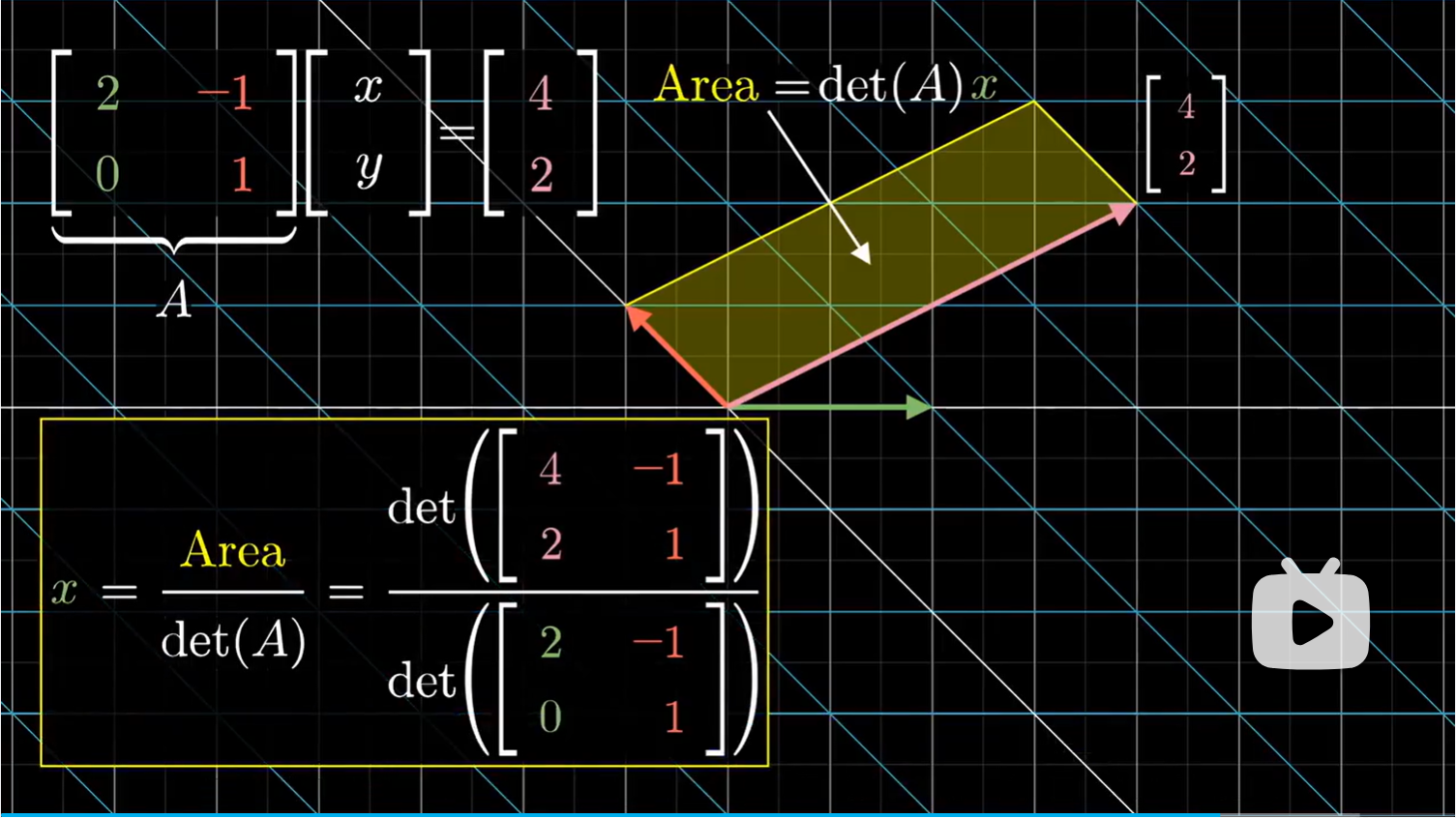
这个线性方程组的解法,就被称为克莱姆法则。
对于三维,或者在更高维的情况下,也同样适用。
好啦,这就是”线性代数的本质“系列的全部内容了,如果读者去看过全部的视频并理解了的话,相信已经对线性代数的潜在直观有了深厚的理解。虽然这和学习完整的课程并不是一回事,但是如果对线性代数具备了正确的直观,那么在以后的学习中,就会更加高效。愿各位在运用直观思维时找到乐趣,同时也祝各位今后的学习顺利!

转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可联系QQ 643713081,也可以邮件至 643713081@qq.com
文章标题:密码学基础之线性代数Ⅱ
文章字数:11.4k
本文作者:Van1sh
发布时间:2023-09-13, 07:00:00
最后更新:2023-10-24, 10:11:32
原始链接:http://jayxv.github.io/2023/09/13/密码学基础之线性代数Ⅱ/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

