def__byte_shuffle_re(s: int) -> int: s = bin(s)[2:].zfill(8) idx = list(range(8)) random.shuffle(idx) s = ''.join([s[idx.index(i)] for i in range(8)]) return int(s, 2)
defbits_shuffle(s: bytes) -> bytes: s = bytearray(s) for i in range(len(s)): s[i] = __byte_shuffle(s[i]) return bytes(s)
defbits_shuffle_re(s: bytes) -> bytes: s = bytearray(s) for i in range(len(s)): s[i] = __byte_shuffle_re(s[i]) return bytes(s)
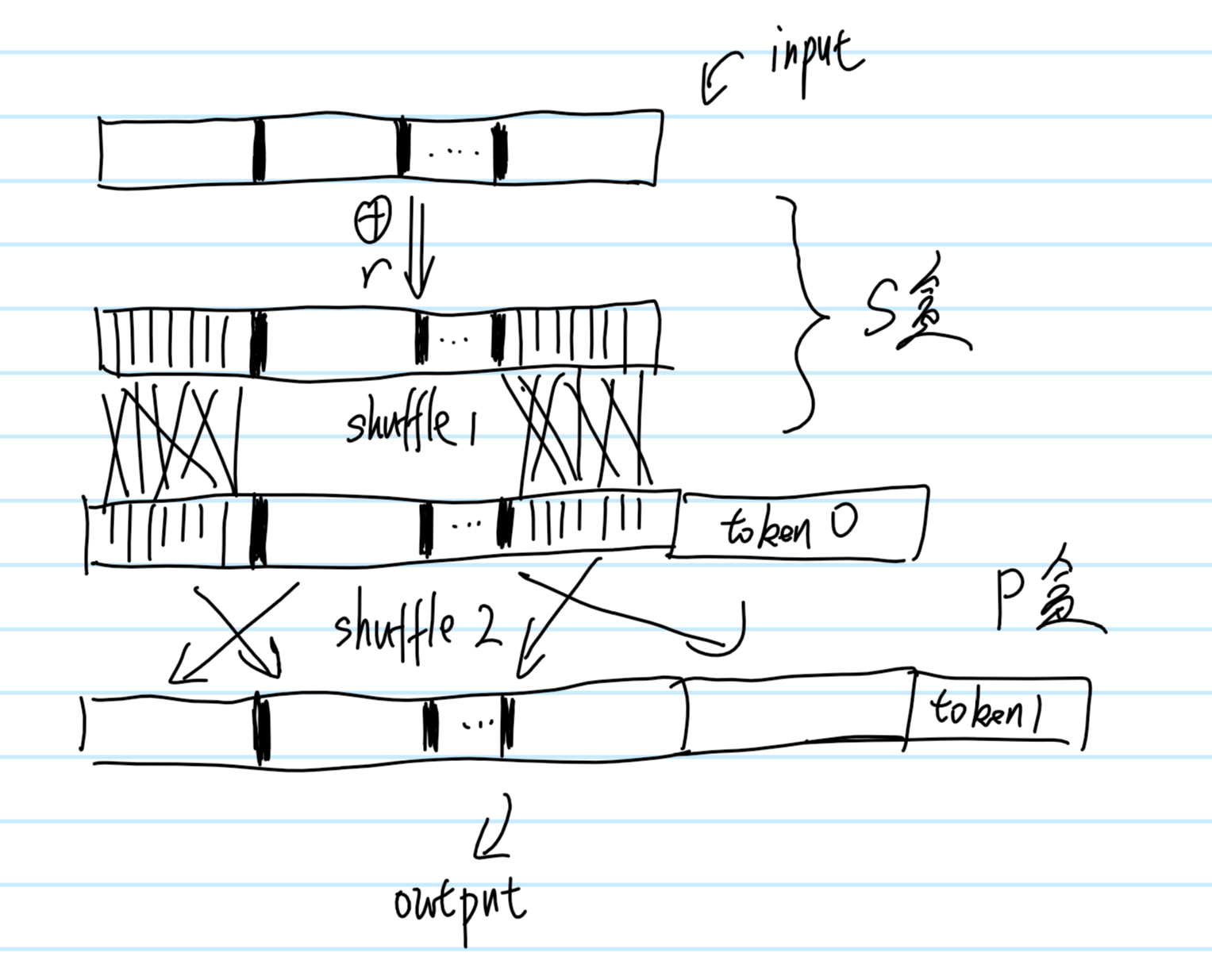
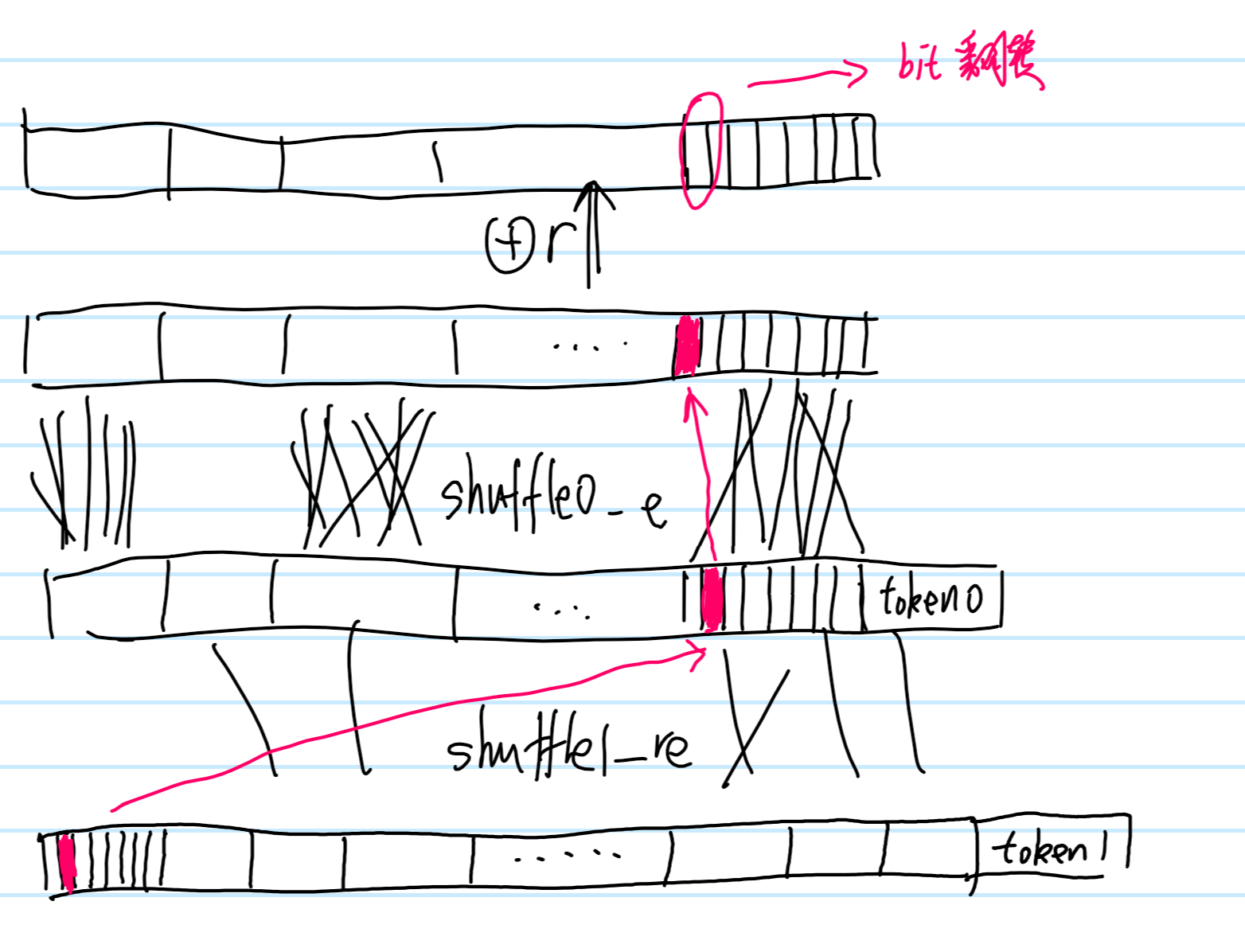
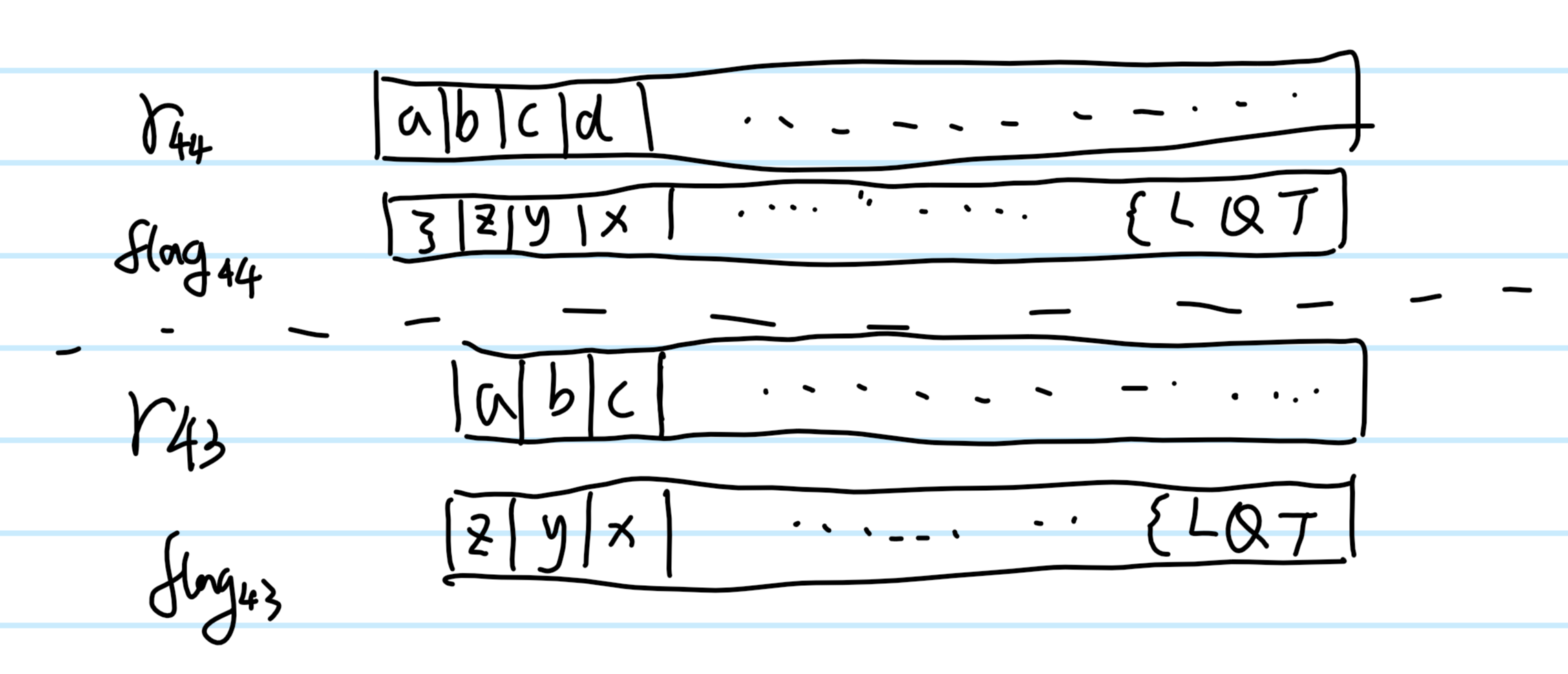
如上图所示,flag加密的时候是44个字节,这里异或的时候用的是小端序,所以最后四个字节 ” } z y x “,会和 “ a b c d “进行异或,但如果解密的时候,你少传了一个字符,把最后一个 ‘}’ 给丢掉了,那么他在异或的时候,会是” z y x” 和 “a b c” 异或,就这么错位了。所以解密的时候就会寄,如果运气好可见的话,你还能看到flag的前面40个字节,运气不好就会报字符非法了(算每一个字符合法概率为1/2,都合法只有1/8的概率)。(虽然后续会有补救的方法,但确实太过于麻烦)所以我们这里选5字节,多出的一字节要是解密失败——报位置44处非法字符,那说明我们的token0顺序对了,我们换一个字节继续试就好了。
from Crypto.Util.number import * from TQLOPT import *
flag_enc = encrypt(flag, flag_token) c = long_to_bytes(int(flag_enc,16)) table_from_to={} token1to=[] c = list(c) # 异或flag_enc的各个bit以得到token1所对应的乱序规则 for index in range(len(c)-4): # 最后四个字节是token1 times = 0#记录invalid次数 for i in range(8): tempc = c.copy() tempc[index] ^= 1 << i tempstr = ''.join(chr(i) for i in tempc) tempbytes = tempstr.encode('latin1') templong = bytes_to_long(tempbytes) temphex = hex(templong)[2:].rjust(104,'0') # 这里只是想把异或c的一个bit然转成hex而已,绕了一圈属于是 try: decrypt(temphex) except InvalidChar as e: # 由于是本地调试,我直接捕获异常了,如果是远程交互,可能还需要写一个正则匹配一下返回值 fr0m = str(e) times += 1 except DangerousToken: pass if times == 8: # 如果八次全错,说明我们改到token0了,记录下位置 token1to.append(index) else: table_from_to[fr0m] = index # 至此,我们获取到了密文中token0的位置,已经相应的token1所对应的映射关系 table_from_to # 故技重施,加密一个45字节的msg,获取token1' 已经其对应的映射关系 table11_to_from,这里反正记是方便后面的调用
c = long_to_bytes(int(msg_enc,16)) c = list(c) for index in range(len(c)-4): times = 0 for i in range(8): tempc = c.copy() tempc[index] ^= 1 << i tempstr = ''.join(chr(i) for i in tempc) tempbytes = tempstr.encode('latin1') templong = bytes_to_long(tempbytes) temphex = hex(templong)[2:].rjust((45+8)*2,'0') try: decrypt(temphex) except InvalidChar as e: fr0m = str(e) times += 1 except DangerousToken: pass if times == 8: token11to.append(index) else: table11_to_from[index] = fr0m # 现在我们按照table_from_to,把flag的顺序调回来,
c = long_to_bytes(int(flag_enc,16)).decode('latin1') rec = [] for i in range(52-8): rec += c[table_from_to[str(i)]] token0 = ''.join(c[token1to[i]] for i in range(4))
from itertools import permutations for each in list(permutations(token0,4)): token00 = list(each) rectmp = rec+['0'] + token00 #然后加上一个字节,加上24种token0,
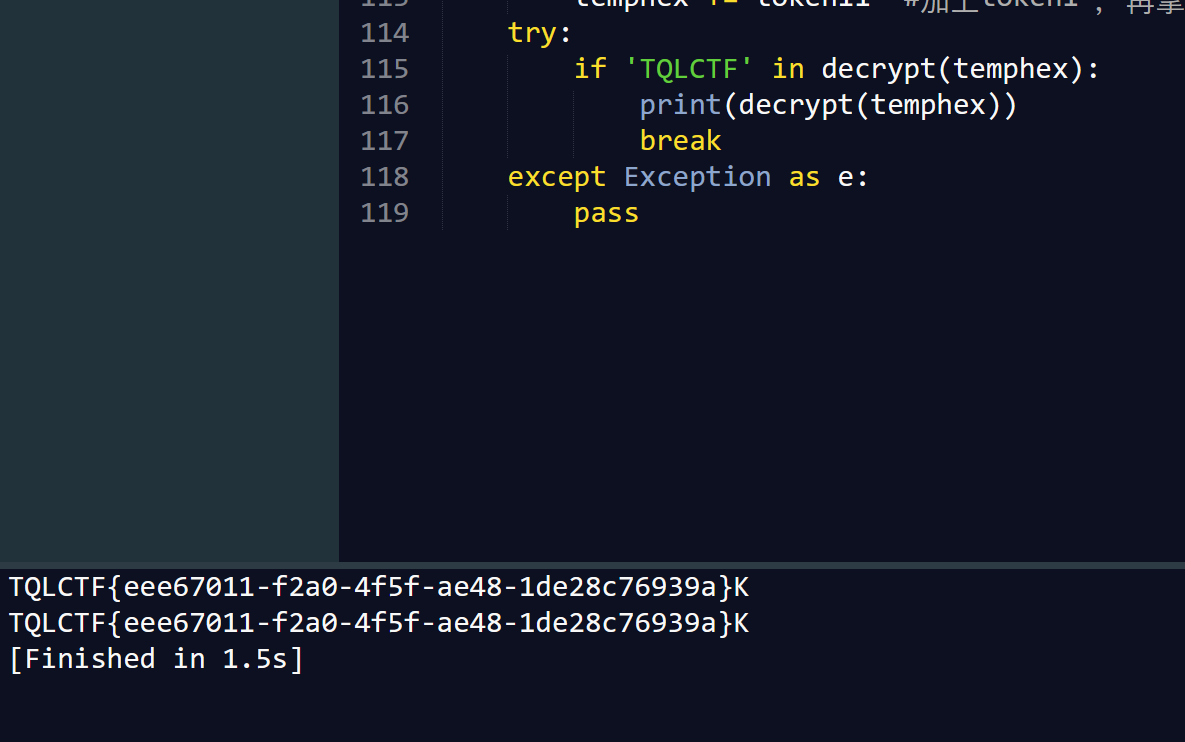
rec_s = "" token00index=0 for i in range(53-4): if i in table11_to_from.keys(): rec_s += rectmp[int(table11_to_from[i])] # 按照table11_to_from乱序,剩下四个空用token0去补 else: rec_s += token00[token00index] token00index += 1 tempbytes = rec_s.encode('latin1') templong = bytes_to_long(tempbytes) temphex = hex(templong)[2:].rjust((45+4)*2,'0') temphex += token11 #加上token1',再拿去解密 try: Token0=0 if'TQLCTF'in decrypt(temphex): print(decrypt(temphex)) exit() # 运气好一步到位 except InvalidChar as e: if str(e) == '44': Token0 = token00 #如果44出错说明token0对了,去换字节就好 break ifnot Token0: #实测下来发现就算token0对了,它解密后最开头的四个字节还是会异或出错,这就不是很清楚原因了,直接再来一遍好了。 print("Try again") exit() table = list(string.digits + string.ascii_letters + string.punctuation)
for each in table: rectmp = rec+[each] + Token0 # 故技重施2,换字节,直到最后一个异或完是可打印字符 rec_s = "" token00index=0 for i in range(53-4): if i in table11_to_from.keys(): rec_s += rectmp[int(table11_to_from[i])] # 按照table11_to_from乱序,剩下四个空用token0去补 else: rec_s += Token0[token00index] token00index += 1 tempbytes = rec_s.encode('latin1') templong = bytes_to_long(tempbytes) temphex = hex(templong)[2:].rjust((45+4)*2,'0') temphex += token11 #加上token1',再拿去解密 try: if'TQLCTF'in decrypt(temphex): print(decrypt(temphex)) break except Exception as e: pass